
论文阅读: Transformer
Published:
读 Transformer | 集中一下注意力
[TOC]
题目:Attention is all you need
作者:
链接:
代码:
推荐阅读:
摘要
- 主流的序列转录模型主要依赖于复杂的循环或卷积网络,一般用 encoder 和 decoder 的架构。性能最好的模型通常在编码器和解码器之间,使用一个注意力机制。(我要做序列到序列的生成,但是现在主流模型在干什么)
- 提出了一个新的简单的架构,仅仅依赖于注意力机制,没有用循环和卷积。做了两个机器翻译实验,显示模型在性能上特别好。英语到德语,英语到法语。
结论
- 介绍了 Transformer 这个模型,是第一个仅仅使用注意力,做序列转录。把所有循环层换成了多头注意力。
- 在机器翻译任务上,比其他架构训练快很多,性能好。
- 对于这种基于纯注意力机制的模型非常激动,想用在别的任务上。
- 代码通常放在摘要的最后一句话。
导言
- 摘要的扩充。时序模型常用的 RNN,LSTM,GRU。这里面有两个主流模型,一个叫语言模型,另一个当输出结构化信息比较多时,用编码器解码器架构。
- RNN 的特点和缺点。给定一个序列,计算是从左往右逐步往前做。假设序列是一个句子,一个词一个词来看。对第 t 个词,计算一个输出 h_t,也叫隐藏状态,由前一个词的隐藏状态 h_t-1 和当前第 t 个词本身决定。把前面学到的历史信息通过 h_t-1 放到当下,和当前的词做计算,得到输出。问题:逐步计算难并行。且历史信息是逐步向后传递的,如果时序较长,在很早期的时序信息在后面可能会丢掉。如果不想丢掉要做很大的 h_t,每个时间步都存,内存开销大。
- attention 在 RNN 上的应用。本文之前,attention 已经被成功用于编码器解码器。主要用在怎么把编码器的东西有效传给解码器,和 RNN 一起用。
- 提出的 Transformer 纯用 attention,所以并行度很高,在较短的时间内做到比之前更好的结果。
相关工作
- 如何使用CNN替换掉RNN,来减少时序计算。主要问题是用卷积网络对于比较长的序列难以建模,因为卷积做计算时,每一次要看一个比较小的窗口,例如 3x3,如果两个像素隔的很远,要叠很多层,才能把两个远的像素融合起来。
- 如果使用注意力机制,每次能看到所有像素,一层就能看完整个序列。但是卷积好的地方在于可以做多输出通道,一个输出通道可以认为是去识别不一样的模式,因此提出了多头,模拟卷积网络多输出通道的效果。
- 自注意力机制,前面有人提出的。
- memory networks
- To the best of our knowledge,Transformer 是第一个只依赖于自注意力来做 encoder decoder 架构的模型。
- 关键是讲清楚跟你论文相关的那些论文,和你的联系是什么,你跟他们的区别是什么。
模型架构
- 序列模型里,现在比较好的是编码器解码器架构。对编码器来讲,会将输入(长为 n 的 x_1 到 x_n 的序列)表示为也是长为 n,但是其中每一个 z_t 对应的是 x_t 的向量表示。假设输入是句子,就是第 t 个词的向量表示。编码器的输出就是原始输入变成机器学习可以理解的一系列向量。解码器拿到编码器输出,生成一个长为 m 的序列,和 n 可能不一样长。编码器里能一次性看全整个句子,而解码器里,词是一个一个生成的,叫自回归,输出又是输入。
- 给定 z,生成第一个输出 y1,拿到 y1 后生成 y2,要生成 y_t 需要拿到之前所有的 y1 到 y_t-1,在翻译时是一个词一个词往外蹦。在过去时刻的输出也会作为当前时刻的输入。
总体
- Transformer 使用了编码器解码器架构,具体来说是将一些自注意力和 MLP 堆在一起。架构初步介绍:首先看到是编码器解码器架构。
- 比如中文翻英文,编码器输入是中文句子。解码器在做预测时是没有输入的,训练时把解码器在之前时刻的一些输出,作为输入。shifted right:一个一个加在后面,往右移。输入先进入一个嵌入层,进来是一个词,把它表示成向量。
- 编码器的 block:多头注意力,MLP,残差连接,normalization。编码器的输出作为解码器的输入,解码器比编码器多了一个 masked 多头注意力。
编码器
- N = 6 个完全一样的 layer,每个 layer 里有两个 sub-layer,一个是多头注意力,一个是 MLP,对每个子层用了一个残差连接,最后用了 layer normalization。
- 为了简单起见,残差连接需要输入和输出大小一样(如果不一样要做投影),把每个层输出的维度变为 512,用固定长度表示,使得模型相对简单,要调的超参数少,只有层数和维度
- 这和之前 CNN 和 MLP 不一样,通常会把维度往下减。CNN 是空间维度往下减,channel 维度往上拉。
LayerNorm
- 和 batchnorm 对比,为什么在变长的应用里不用 batchnorm?
- 考虑最简单的二维输入情况,[BS, d_model]
- batchnorm:对每个特征列,把它在一个 mini-batch 里的均值变成0,方差变成1(就是把向量本身的均值减掉,除以方差)。训练时,均值方差是在小批量里算的。预测时,算全局的均值,整个数据扫一遍,在所有数据上的均值方差存起来。bn还会学一个lamta,gama,可以把这个向量通过学习,放成任意方差,均值为某个值的东西。
- LayerNorm:对每个样本做 normalization,把每个行变成均值0方差1,一行表示一个样本。也可以理解为把数据转置一下,做bn,再转置回去。
- Transformer 里输入是序列,三维,[BS, seq_len, d_model]
- batchnorm:按蓝线切,对特征列,切一个平面出来,理解为这种切法要保留完整的 batch 和 seq 维度。每次取一根特征,把这个二维 [BS, seq_len, 1] 的所有元素,变成均值0方差1。也可以理解为把二维拉成一个向量,和之前一样。
- LayerNorm:按黄线切,切一个样本出来,理解为这种切法要保留完整的 seq_len 和 d_model 维度。
- 为什么 LayerNorm 用的多一点?
- 在序列模型里,每个样本的长度可能发生变化,主要问题是算均值和方差。通常在 batch 内部对齐,长度不一样补零。
- 如果是 batchnorm,如果样本长度变化比较大,每次做小批量算的均值方差的抖动相对较大。另一个问题是,预测时要记录全局的均值方差,如果碰到新的预测样本特别长,训练时没见过,之前算的均值方差就不好用了。
- LayerNorm 是对每个样本自己算,不需要全局的均值方差,不受样本长短影响,相对来说更稳定。也有从梯度方面的解释。 、
- BN :使损失平面更加平滑,加快收敛。但 batch size 小的时候效果差,因为 BN 用小批量数据的均值方差来模拟全部数据。CV 用 BN 是因为不希望对通道维度归一化,会造成不同模式信息的损失。而 NLP 因为句子长度不一致,且各个 batch 之间的信息没什么关系,因此只考虑句子内。
解码器
- N = 6,有两个和编码器一样的 sub-layer,残差连接,LN,不同点在于第三个子层。
- 解码器是自回归,当前的输入是之前时刻的输出,意味着在做预测时,不能看到后面时刻的输出,但是注意力机制里,每次可以看到完整的输入,在这个地方要避免,通过掩码。
- 解码器在训练时,预测第 t 个时刻的输出时,不应该看到 t 时刻之后的那些输入,保证训练和预测时的行为一致。
注意力层
- 注意力函数是将一个 query 和一些 key-value 对映射成一个输出的函数,这里qkv都是一些向量。
- 具体来说,output 是 value 的一个加权和,所以输出的维度和 value 维度一样。
- 权重怎么来的:对于每一个 value 的权重,是这个 value 对应的 key 和查询 query 的相似度算来的。这个相似度 compatibility function 不同注意力机制有不同算法。
- 假设有三个 value 和三个对应的 key,假设现在给一个 query,这个 q 和第一第二个 k 比较近,输出是这三个 v 相加,但是前两个权重会大一点,因为这个权重等价于 query 和对应 key 的相似度。
- 同理,假设再给一个 query,但是和最后一个 key 比较像,那算它的 v 的时候,会发现它对后面的权重比较高一点,中间权重还不错,第一个权重小。会得到一个新的输出,虽然 key value 并没有变,但是随着 query 的改变,因为权重分配不一样,导致输出不一样。这就是注意力机制(理解为 query 比较特殊)。
- 本质:根据某个 query 和所有 key 的相似度,动态调节 value 中对应位置 token 的语义组成。一句话,V 根据 QK 的相似度来调整该位置的自己。假设在编码器,输入
making the registration more difficult,query 是making,和more,difficult的相似度最高,则 value 中making对应位置的 token 组成就变成了这三个词的加权和。
import torch
if __name__=='__main__':
seq_len = 4
d_model = 2
QK = torch.randn((1, seq_len))
V = torch.randn((seq_len, d_model))
QK[0][1] = -10000
score = torch.softmax(QK, dim=-1)
print(V)
print(score)
print(torch.matmul(score, V))
'''
tensor([[ 0.6679, 0.7001],
[-0.8284, 2.1086],
[-1.0221, -1.3357],
[-1.3934, 0.9698]])
tensor([[0.6880, 0.0000, 0.1649, 0.1471]])
tensor([[0.0860, 0.4040]])
'''
Scaled Dot-Product Attention
- 因为不同的相似函数导致不一样的注意力版本,Transformer 用的是最简单的注意力机制,里面的 query 和 key 长度是等长的,都是 d_k,value 是 d_v,因此输出也一样是 d_v。
- 具体计算:每个 query 和 key 做内积,把它作为相似度。两个向量做内积:如果两个向量的 norm 是一样的,那么内积值越大,也就是余弦值,那么表示这两个向量的相似度越高。(内积为零,两向量正交,没有相似度)
- 算出内积后,除以根号 d_k(向量长度),再用 softmax 得到权重。给一个 query,假设给 n 个 key-value pair,就会算出 n 个值,因为这个 query 会和每个 key 做内积。算出来放进 softmax 会得到 n 个非负,和加起来等于 1 的权重。最后作用到 value 上得到输出。
- 实际中肯定不是一个一个运算。query 可以写成一个矩阵,有 n 个 query:Q [n, d_k]。同理 K [m, d_k](query 的个数可能和 key-value 不一样,但长度一样,才能做内积),Q 和 K 乘得到 [n, m],每一行表示一个 query 对所有 key 的内积值。除以根号 d_k,再对每一行内部做 softmax,行与行之间是独立的。得到权重,乘 V [m, d_v],得到 [n, d_v],其中每一行就是我们要的一个输出。
总结:对于 n 个 query 和 m 组 key-value 对,可以通过两次矩阵乘法加速计算。qkv 实际中对应序列,可以并行计算序列里的每个元素。
- 一般有两种常见注意力机制:加型,可以处理 query 和 key 不等长的情况。点积,其实和本文一样,除了本文除了根号 d_k。这两种注意力机制都差不多,选用点乘是因为实现简单高效,两次矩阵乘法就能算好。
- 为什么要除以根号 d_k:当 d_k 不是很大的时候,除不除没关系。但是当 d_k 比较大的时候,也就是两个向量长度比较长的时候,做点积时,这些值可能会比较大,也可能比较小。这些值之间相对的差距会变大,导致最大的那个值 softmax 后会更加靠近于 1,剩下那些值会更加靠近于 0,也就是值会更加向两端靠拢。这种情况下算梯度会比较小,因为 softmax 最后的结果希望预测值置信的地方尽量靠近 1,不置信的地方尽量靠近 0,这样可以说收敛差不多了,这时候梯度就会变得比较小,就会跑不动。Transformer 一般用的 d_k 比较大 512,所以除以根号 d_k。
- 为什么点积会导致输出值的相对差距变大:假设 q 和 k 的值是独立随机变量均值 0 方差 1,点积后的均值 0 方差为 d_k。
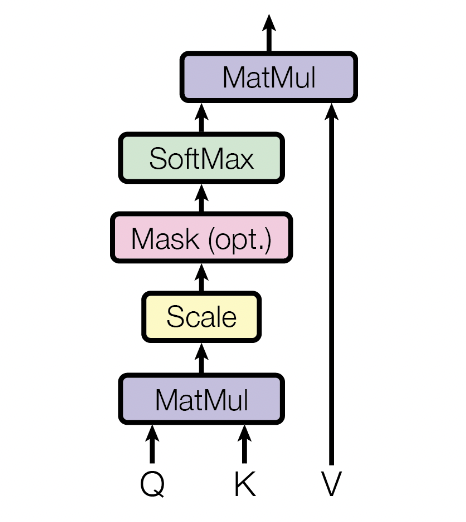
- 计算图:两个矩阵 Query 和 Key,做矩阵乘法,然后再除以根号 d_k,mask,然后做 softmax,出来的结果最后和 Value 矩阵做矩阵乘法,得到输出。
- 怎样做 mask:掩码主要是为了避免在第 t 时间的时候看到以后时间的东西。具体来说,假设 query 和 key 等长,长度都为 n,在时间上可以对应起来。对于第 t 时刻的 q_t,计算时应该只看 k1 到 k_t-1,而不应该去看 k_t 和他之后的东西,因为 k_t 在当前时刻还没有。但是注意力机制其实会看到所有,q_t 会和所有 k 里面的全部东西做运算,k1 一直算到 k_n。其实算是可以算的,算出来之后,只要保证在计算权重时,不要用到后面一些东西就行。mask 具体来说,对于q_t 和 k_t 和它之后计算那些值,换成一个非常大的负数,在进入 softmax 做指数的时候就会变成 0,导致 softmax 之后这部分对应的权重都会变成 0,只会前面 k_1 到 k_t-1 这些值出效果。这样在算 output 时只用了 Value 对应的 v1 到 v_t-1 的结果就用上了它,而后面的东西没有看。
- 总结:mask 效果就是,在训练时,让第 t 个时间的 query 只看对应的前面那些 key-value pair,使得做预测时,能跟现在一一对应上。
Multi-Head
- 与其做单个的注意力函数,不如把整个 query,key,value 投影到一个低维,投影 h 次,再做 h 次注意力函数,把每个函数的输出并在一起,再投影回去,得到最终输出。
\(MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O\) \(head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\)
- 为什么要做多头:dot-product 注意力里面没有什么可学习参数,具体函数就是内积。为了识别不一样的模式,希望有一些不一样的计算像素办法。 用要学的 W 投影到低维,h 次机会,希望学到不一样的投影方法,使得投影进去的度量空间里,能够匹配不同模式,最后拼回来再做一次投影。(W_Q,W_K,W_V 目的是把输入 QKV 投影到不同空间,识别更多模式)
- h = 8,因此 d_k = d_v = d_model / h = 64,虽然是非常多的小矩阵乘法,但是可以通过一次矩阵乘法实现。
Transformer 模型里如何使用注意力
- 三种使用情况
编码器的自注意力:编码器的输入 [BS, n, d_model],注意力层三个输入,由一根线复制三下,表示同样一个东西,既作为 key,value,也作为 query。所以叫做自注意力机制,qkv 其实是一个东西,就是自己本身。对每个 query,计算一个输出,输出其实就是 value 的加权和,权重来自 query 和 key 的相似度。不考虑多头和投影,其实qkv都是一个东西,所以输出本质上是输入的加权和,权重来自于自己本身,和各个向量之间的相似度,跟自己算肯定是最大的。多头会学习 h 个不一样的距离空间,使得输出会有一点不一样。
解码器的自注意力:和编码器一样,一个输入复制三次。[BS, m, d_model],唯一不同在于 mask,只看前面部分,后面的权重设成零。
交叉注意力:不再是自注意力,key 和 value 来自编码器输出,query 来自解码器自注意力层的输入。对解码器的每一个输出作为 query 算一个输出,来自编码器输出的加权和,权重的粗细程度取决于解码器 q 和编码器 k 的相似度。把编码器的输出,根据解码器想要的东西给拎出来。例如英文翻译中文,
hello world --> 你好世界,好作为 query 时,去看hello这个向量应该会相近一点,给一个比较大的权重。根据解码器输入的不一样,根据当前那一个向量,去在编码器的输出里面挑我感兴趣的东西,也就是你注意到你感兴趣的东西,那些不那么感兴趣的东西就可以忽略掉。也是 attention 如何在编码器和解码器之间传递信息的时候起到的作用。
Point-wise Feed-Forward
- 其实就是一个 MLP,不一样的是分别用在每个位置上。pisition 指输入序列的每个词,就是一个点。把一个 MLP 对每一个词作用一次,对每个词作用的是同样一个 MLP。这就是 point-wise,说白了就是 MLP,只是作用在最后一个维度。
- 单隐藏层的 MLP,中间隐藏层把输入扩大四倍,最后输出的时候大小回去。
图解
- 考虑最简单的情况,没有残差连接,没有LN,单头 attention。
- 输入是长为 n 的一些向量,进入 attention 后得到同样长度的输出。最简单的注意力是对输入做一个加权和,之后进入 point-wise 的 MLP,这里每个 MLP 的权重是一样的,每个 MLP 对每个输入的点做运算,得到一个输出。
- attention 起的作用:把整个序列里的信息抓取出来,做一次汇聚(aggregation),所以单个向量就已经包含了它对序列中感兴趣的东西,信息已经抓取出来了。以至于在做投影 MLP 的时候,映射成更想要的语义空间的时候,因为单个向量已经含有里序列信息,所以每个 MLP 只要对每个点独立做就行了。因为在 attention 层里序列信息已经被汇聚完成,所以后续 MLP 部分是可以对序列分开成单个向量做的。
- 整个 Transformer 是如何抽取序列信息,然后把这些信息加工成最后要的那个语义空间的向量。
- 对比 RNN:输入一样是一些向量,对于第一个点,也是做一个线性层,做一个最简单的,没有隐藏层的 MLP,纯线性层。第一个点就是直接做,对于下一个点,怎样利用序列信息:还是用同样的 MLP,权重也和之前一样,但是时序信息是,把上一个时刻的输出放回来,和当前时刻的输入一起并进去,就完成了信息的传递,得到当前输出。
- RNN 和 Transformer 一样都是用一个 MLP 来做语义空间的转换,不一样的是如何传递序列信息。RNN 是把上一个时刻的信息输出传入下一时刻做输入,Transformer 用 attention 层在全局拿到整个序列信息,然后再用 MLP 做语义的转换。关注点都在于怎样有效使用序列信息。
Embedding
- 因为输入是一个个词(词元 token),需要把它映射成一个向量。embedding 就是说,给任何一个词,学习一个长为 d 的向量来表示它。
- 三个 embedding:编码器、解码器输入,最后 softmax 前面那个线性层。这三个用一样的权重。
- 权重乘了根号 d_model。因为在学 embedding 时,会把每个向量的 L2 norm 学成比较小的,例如 1。即不管维度多大,最后平方和都为 1。也就是说,维度一大,学的权重值就会变小。由于后面要加上位置编码,它不会随着长度变长,把 norm 固定住。所以乘根号 d_model 之后,使得两者相加的时候在 scale 上差不多,就是做了一个 hat。
Positional Encoding
- attention 没有时序信息。输出是 value 的一个加权和,权重是 query 和 key 之间的距离,和序列信息是无关的,不会看 k-v 对在序列里的哪个位置。也就意味着,如果给一句话,把顺序打乱之后,attention 出来的结果还是一样的。顺序会变,但是值不会变,这就有问题了。词打乱语义肯定会发生变化,rnn 是上一时刻的输出作为下一时刻的输入来传递历史信息,本来就是时序。
- 做法是在输入里面加入时序信息。例如一个词在位置 i,把 i 这个位置的编码数字加到输入里。
- 大概思路:计算机里例如用 32 位来表示数字,每个 bit 上有不同的值,来表示整数,可以理解为一个数字是用长为 32 的一个向量来表示的。现在同样用长为 512 的向量来表示一个数字,也就是一个位置,具体的值是由周期不一样的 sin 和 cos 函数值算出。这个长为 512,记录了时序信息的向量和嵌入层相加,就把时序信息加进了数据。(大小为 [max_len, d_model],即一个位置由一个长为 512 的向量表示)
- 输入 n 个词的序列进入 embedding 层,每个词都会拿到一个长为 512 的向量表示,然后 positional encoding 就是这个词在句子中的位置,告诉它位置,返回一个长为 512 的向量,表示这个位置。位置编码值在 [-1, 1] 之间抖动,embedding 乘根号 d_momdel 使得每个数字也差不多在 [-1, 1] 的数值区间里。
为什么要用自注意力
- 比较了四种不一样的层:自注意力,循环层,卷积层,受限的自注意力。
- 比较计算复杂度(越低越好);顺序的计算(越小越好)在算一个 Layer 的时候,下一步计算必须要等前面多少步计算完成,越不用等并行度越高;一个信息从一个数据点走到另外一个数据点要走多远(越短越好)。
- n:序列长度。d:向量长度。
- attention:几个矩阵运算。query 矩阵乘 key 矩阵,其他矩阵运算复杂度一样。矩阵乘法并行度高。任何 query 和任何很远的 k-v pair 只要一次就能过来。(计算上好,信息揉合性好)
- rnn:复杂度取决于 n 大还是 d 大,如果 n 大自注意力会贵一点。现在 n 是几千,d 有 2048,差不多。但是 rnn 当前时刻的词要等前面那个词完成。起点到最后一个点的信息需要走 n 步才能传递,特别长序列处理不好,信息走丢了。
- 卷积:在序列上用一维卷积,并行度高,信息在窗口 k 距离内能一次传递。
- 受限自注意力:query 只和最近的 r 个邻居运算。但是长距离的两个点需要走几步才能过去。实际上用 attention 主要关心,特别长的序列,能够把信息揉的好一点,不用受限版本。
- 实际上是 attention 对整个模型的假设做了更少,导致需要更多数据和更大的模型才能训练出来跟 rnn 和 cnn 同样的效果,导致现在基于 Transformer 的模型都特别大特别贵。
实验
- 英语翻德语,用了 bpe,思想:如果直接把一个词做成一个 token,字典比较大,而且同一个词的不同形式区别模型不知道。bpe 把词根提出来,字典降比较小。37000 token,后期使用时需要一个替换表来重建原始数据。英语德语共享,好处是编码器解码器的 embedding 可以用一个东西(weight tying)。
- 学习率根据模型的宽度算出来,当模型越宽,向量越长,学习率低一点。有 warmup = 4000,从一个小的值满满爬到一个高的值。后面再根据步数按 0.5 次方衰减。学习率基本不用调,adam 对学习率没有那么敏感。
- 正则化:
- 对每个子层(多头,MLP)的输出,在进入残差和 LN 之前,用了 dropout = 0.1,把输出 10% 的元素置成 0,其他值乘 1.1。
- embedding + 位置编码后也用了 dropout。基本对每一个带权重的层,输出都使用了dropout,虽然率不高,但是量多。
- label smoohting:用 softmax 学东西,标号正确的是 1,错误是 0,让正确 label 的 softmax 值逼近 1。但是由于 softmax 是指数,很难逼近于 1。很 soft,需要输出接近无限大的时候才能逼近 1,使得训练比较难。通常可以不要逼近 1,降成 0.9,(这里错误标号对应的和为 0.1?)降的比较狠,降成 0.1:对于正确的词,只要 softmax 输出到 0.1 就行。剩下那些值是 0.9 除以字典大小。会损失 perplexity,模型不确信度,log loss 做指数。但会提升精度和BLEU分数
- 虽然模型看着复杂,其实没多少参数可以调。
讨论
- 没用太多写作技巧,对一篇文章来说,需要在讲一个故事,让读者有代入感,能说服读者。可以把不那么重要的东西放到附录,正文最好讲个故事,为什么做这个事情,设计理念什么样,对整个文章的思考。
- 人对世界的感知是多模态的,Transformer 能把这些所有不同数据都融进来,因为都用一个同样的架构抽取特征,可以抽到一个同样的语义空间,使得可以用文本,图片,语音,视频训练更好更大的模型。
- attention 只是在 Transformer 里起到一个作用,主要作用是把整个序列的信息给聚合起来,但是后面的 MLP,残差是缺一不可的,如果把后面去掉,attention 基本什么东西都训练不出来。所以也不是说只需要注意力就行了。
- attention 根本不会去对数据的顺序做建模,为什么能打赢 rnn,后者显式建模序列信息,理论上应该比 MLP 效果更好。现在觉得 attention 用了一个更广泛的归纳偏置 inductive bias,使得它能处理一些更一般化的信息。这也是为什么说,attention 并没有做任何空间上的假设,它也能跟 cnn,甚至比 cnn 取得更好结果。但是代价是,因为假设更加一般,所以它对数据抓取信息的能力变差了,以至于需要使用更多数据,更大的模型,才能训练出想要的效果。
- 新架构,就用 MLP 或更简单的架构也能在图片或文本上取得好结果。
问题
- Transformer 为什么 Q 和 K 使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
- 为了把输入投影到不同空间,识别更多模式
- softmax 性质:softmax 实际做的是一个 soft 版本的 arg max 操作,如果向量太长,得到的向量接近一个 one-hot(就一个位置是 1,其他 0)。如果 Q=K,注意力分数矩阵可能变成单位矩阵,自注意力退化成 point-wise 线性映射。
- (QK 点乘计算句子中一个词和其他词的相似度,动态调节 value 中对应位置 token 的语义组成。即 V 根据 QK 的相似度来调整该位置的自己,提纯,让每个词关注该关注的部分)
- 为什么不能用加法算 attention 分数?
- 加法用隐藏层,引入额外参数(整体计算量和点积类似?)
- 词向量 embedding 后乘根号 d_model?
- 嵌入层矩阵用 Xavier 初始化参数,方差为 1 / d_model,乘根号 d 使方差为 1
- 其他位置编码
- 旋转位置编码(ROPE):复数域,已知一个词在某位置的向量表示,可以算出它在任何位置的向量表示。生成词向量的时候即生成对应的位置信息。(位置信息已经包含在向量里了?)
- 相对位置编码(RPE):在计算 attention score 和 weighted value 时各加入一个可训练的表示相对位置的参数
- 语言和意识的关系?