
论文阅读: ResNet
Published:
读 ResNet | 图像识别的深度残差学习
[TOC]
题目:Deep Residual Learning for Image Recognition
作者:
链接:
代码:
推荐阅读:
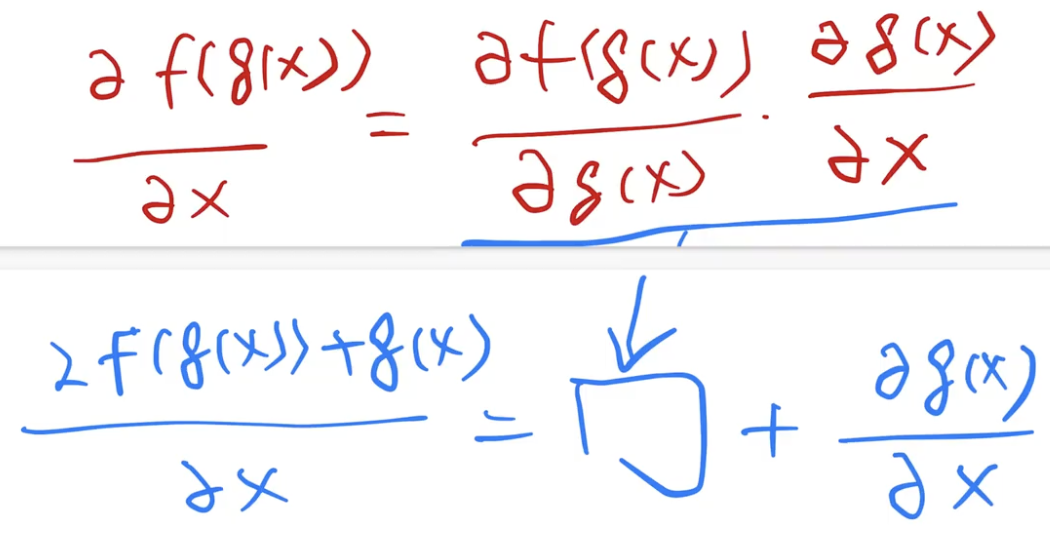
从现在的角度看
- 主要贡献是把残差连接用过来,给了直观的解释,使一个更复杂的模型,如果新加的很多层效果不好,能够 fallback 变成一个简单模型,使模型不要过度复杂化。没有做任何分析,有实验,但没有从方法论,数学上解释为什么。
- 后面说一方面为什么 ResNet 训练快,深层能训练得动,主要是因为梯度上保持的比较好。从反向传播的角度:正常计算梯度,求导用的链式法则,假如上面的浅层网络是 g,新加的层是 f。f(g(x)) 对 x 求导,等价于先 f(g(x)) 对 g(x) 求导,再乘 g(x) 对 x 求导。新加的层越多,梯度的矩阵乘法越多,因为梯度是比较小的,通常是在 0 附近的高斯分布,大部分值接近零。所以很深的时候连乘导致特别小,梯度消失。虽然 BN 有用,但相对来说这个乘积还是比较小。
- 但是如果加了 ResNet,变成 f(g(x)) + g(x) 对 x 求导,前面乘积部分跟之前一样容易很小,但是后面加上了 g(x) 对 x 求导,这部分是浅层网络的梯度,相对来说会大一点。所以对于整体梯度来说,前面部分很小没关系,后面部分可以训练的动。小数加上大数,相对来说梯度还是会比较大。
- 这部分可以用来解释,为什么 ResNet34 比没有加残差的时候精度会好,因为没加残差的时候根本没训练动。没加的时候,sgd 的收敛没意义,假如不降学习率,就收敛在高点了。sgd 所谓的收敛就是说 train 不动了。优化上的收敛是说到比较好的地方。这个地方其实因为做深的时候,用简单的 sgd 训练根本就跑不动,就不会得到比较好的结果,所以只看收敛意义不大。但是现在加了残差连接,梯度比较大,所以没那么容易收敛,导致一直可以往前。
人生就和 sgd 一样,精髓是你得一直能跑得动。如果哪一天跑不动了,梯度没了,就在一个局部的地方出不去了。sgd 的精髓就是要梯度够大,一直能够跑,反正有噪音,慢慢总是会收敛的。所以说只要保证梯度一直够大,最后的结果就会比较好。
- 在 CIFAR10 这么小一个数据集上,为什么过拟合不那么明显。在 CIFAR 上加了一千层以上,没有做特别的 regularization 正则,效果也很好,overfitting 有一点但是不大。现在的 transformer 模型那么大是怎样训练的动,100 billion,一千亿参数为什么不过拟合?很多有意思的工作,其实虽然层数很深,参数很多,但是你的模型因为是这么构造的,使得它的 intrinsic,内在的模型复杂度其实不高了。一旦模型复杂度降低,过拟合就没那么严重。
所谓的模型复杂度降低,不是说不能表示别的东西了,就是说你能更方便的找到一个不那么复杂的模型去拟合数据。不加残差连接,理论上也能学出一个 identity 的东西,也就是后面那些层都不要。但是实际上做不到,因为你没有引导整个网络去这么走,其实达不到这个理论上的结果。一定是你得手动把这个结果加进去,使得它更容易能够训练出来。加了残差之后,使得网络能够学到一个更简单的结构,后面那些层都是零,就前面层有东西。更容易训练出一个简单的模型来拟合数据,等价于降低了模型复杂度。
- 机器学习的 residual 例如 gradient boosting 是在标号上做残差,ResNet 是在 feature 维度上。
摘要
- 问题:深的神经网络难训练。
- 我们干了什么:用残差学习的框架,使得训练非常深的网络比之前容易很多。
- 提出的方法:把这些层作为一个学习残差函数,相对于层输入的方式,而不是和之前一样的学习 unreferenced 的方式。
- 实验表明,残差网络易训练,有很好精度,特别是把层数增加后。152层,比VGG深,还有更低的复杂度。
- 对于视觉任务,深度很重要。把 CNN 主干网络,替换成残差网络,在 COCO 上取得好结果。
本文没结论
图表
- 通常会在第一页放一张好看的图,对问题的描述,主要结果都行,越好看越好。
- Randy,CMU,最后一课,小时候的梦想,如何实现。
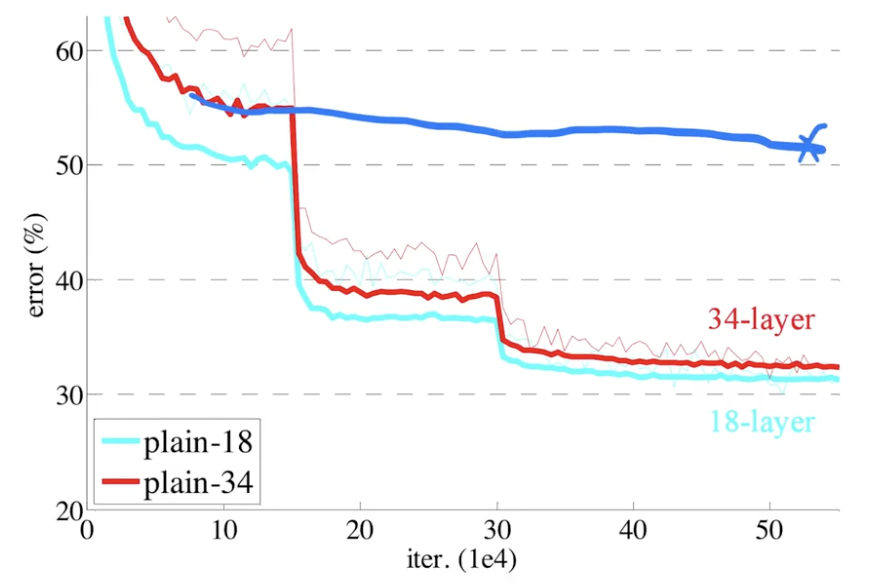
- 左图是训练误差,右图测试误差。在 CIFAR-10 上,用了 20 和 50 层没有加残差的网络
plain。x 轴是迭代次数,y 轴错误率。 - 更深的网络误差率反而更高。表明在更深的网络上是训练不动的,不仅是过拟合,更多是训练误差都不能达到很好效果。
- 这张图表示观察到的现象:更深的网络更难训练。强调本文要解决的问题。
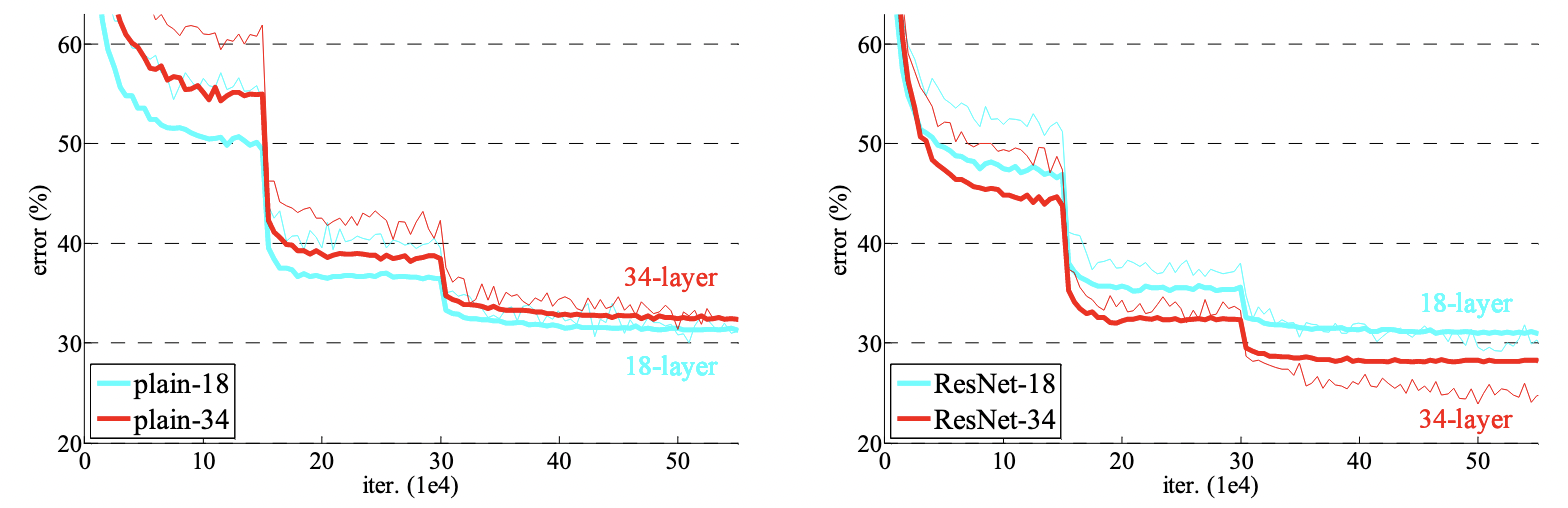
- 右图核心图,用了残差方法后,34层的结果才比18层误差更低。
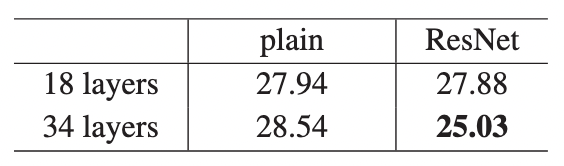
- 对图的总结,图是直观的表示,含有信息更多。表是把数字详细写出来,后面引用者直接对比。
导言
- 深度卷积神经网络好,因为可以加很多层,把网络变深。不同程度的层会得到不同level的feature,低级的视觉特征,高级的语义特征。
- 问题:随着网络变深,学一个好的网络就是简单把所有层堆在一起就行了吗?当网络变深,梯度要么爆炸,要么消失。解决方法:权重在随机初始化时,不要太大太小。在中间加一些 normalization,包括了 BN,使得可以校验每个层之间的输出和梯度的均值方差。使用这些技术是能够训练和收敛深一点的网络。
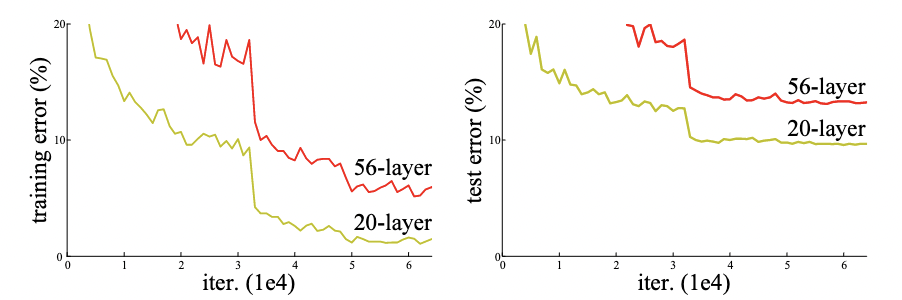
- 但是另外一个问题:当网络变深,性能其实是变差的。这不是因为层数变多,模型变复杂,导致的过拟合,因为训练误差也变高了(过拟合是训练误差低,但测试误差高)。所以更大的网络,虽然似乎是收敛的,但是没有训练到一个比较好的结果。
- 第三段,深入讲加了更多层之后精度变差这个现象。考虑一个浅一点的网络,再多加一些层进去,如果浅的网络效果不错,深的网络是不应该变差的。因为新加的那些层,可以把这些层学成 identity mapping,输入什么就输出什么。但实际上 SGD 找不到这个解。那该怎么办?
- 本文提出一个办法,显示构造出一个 identity mapping,使得深的网络不会变得比浅的网络更差。核心思想:假设已经有了一个浅的网络,输出是 x,要在上面新加一些层,变得更深。但是新加的这些层,不要想和之前一样直接学到满意的映射关系 H(x),而是学 F(x) = H(x) - x,即学到的东西和真实的东西之间的残差。最后整个网络的输出是 F(x) + x,等价于我们想学到的 H(x)。

- 他们假设显示构建的这种残差映射,比原始的,没有依据的映射关系更容易优化。特别是在 identity mapping 是最优解的情况,让残差为 0 更容易,相比于堆非线性层去拟合 idetity mapping。
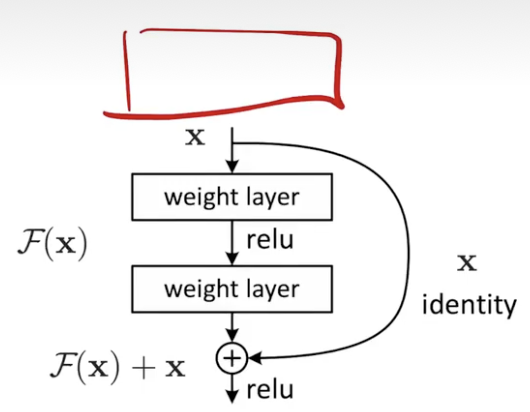
- 浅的网络输出是 x,新加的这些层学习目标是 F(x) = H(x) - x。
F(x) + x 在神经网络实现叫做 shortcut connections,做的是 identity mapping。不会增加任何要学习的参数,就不会增加模型复杂度,也不会让计算量变高,因为就是个加法。整个网络和之前基本没有变,只是在实现上加了点东西。这两段主要讲了提出的方法,以及 residual 到底在干什么事。
- 导论是摘要的增强版本,结果上说的东西更多一点,主要解释了 residual 干什么。我解决了一个什么问题,问题是什么,我的一些猜想,具体整个东西的设计是什么样的。
- 写法上好的部分:intro 是摘要的扩充版本,也是对整个工作比较完整的描述。
相关工作
- residual 在机器学习或统计里用的更多,线性模型最早的解法就是不断靠residual迭代。机器学习的 gradient boosting 不断通过残差学习一个网络,把一些弱的分类器叠加起来,变成一个强的分类器。
- shortcut connection 过去用的比较 fancy 相对复杂一点,这里就是一个加法,最简单的做法。
- resnet 不是第一个提出 residual 或 shortcut,很多经典文章里的技术不是原创的,但一篇文章之所以成为经典,不见得它一定要原创性的提出什么。它可以是把之前一些东西很巧妙的放在一起,能解决一个现在大家比较关心的问题。现在写任何一个东西很有可能会发现前面有人做过了,很多事没关系的,在文章里写清楚,前面谁谁做过了,现在我跟他们有什么不一样地方,比如用同一个东西解决了一个新的问题。可能之前工作太久远,提出一个东西,觉得自己可能是第一个 to our best knowledge。在对待技术的原创性来讲要稍微客观容忍,对研究者来讲不要觉得说,什么东西都被做过了,那我没什么东西可做了,其实也不是这样子的。现在可能问题是同一个问题,但是数据量更大,计算能力更强,新的挑战。旧的技术有新的应用和意义。
residual network
残差连接如何处理输入和输出形状不同的情况:
- 在输入和输出上添加一些额外的 0,使得形状对应,可以做相加。
- 投影:通过 1x1 卷积,空间维度上不变,主要在通道维度上改变。使得输出通道是输入通道的两倍。
- 如果把输出通道翻倍,则输入的高和宽通常要减半。用 stride = 2,使得在高宽和通道上都能匹配。
实现细节:
- 用了一些正常的 practice:
- 把短边随机采样到 [256, 480]。随机放到比较大的地方的好处是,在做随机的 224x224 切割时,随机性更多一点。
- 水平翻转
- 每个像素均值都减掉了。
- 标准颜色增强。简单的在 rgb 上把亮度,饱和度各种地方调一调,photoshop。
- batch normalization
- 权重初始化和自己之前一篇文章相同
- batch size = 256
- lr = 0.1,错误率平的时候除以 10
- iteration = 60 x 10^4。建议是写 epoch,扫了多少遍数据,因为iteration和BS相关
- weight decay = 0.0001,momentum = 0.9
- 没用 dropout,因为没有全连接层。
- 测试时,用了标准的 10 个 crop-testing,给到测试图片,在里面随机或按规则采样 10 个图片,在每个子图上做预测,最后把结果平均。好处是,因为训练是每次随机取图片,测试也大概模拟这个东西,做10次预测也降低方差。还在不同分辨率上采样。实际上用的比较少,不刷榜测试太贵了。
实验
- 包括怎样评估ImageNet,和不同版本的ResNet如何设计
架构细节
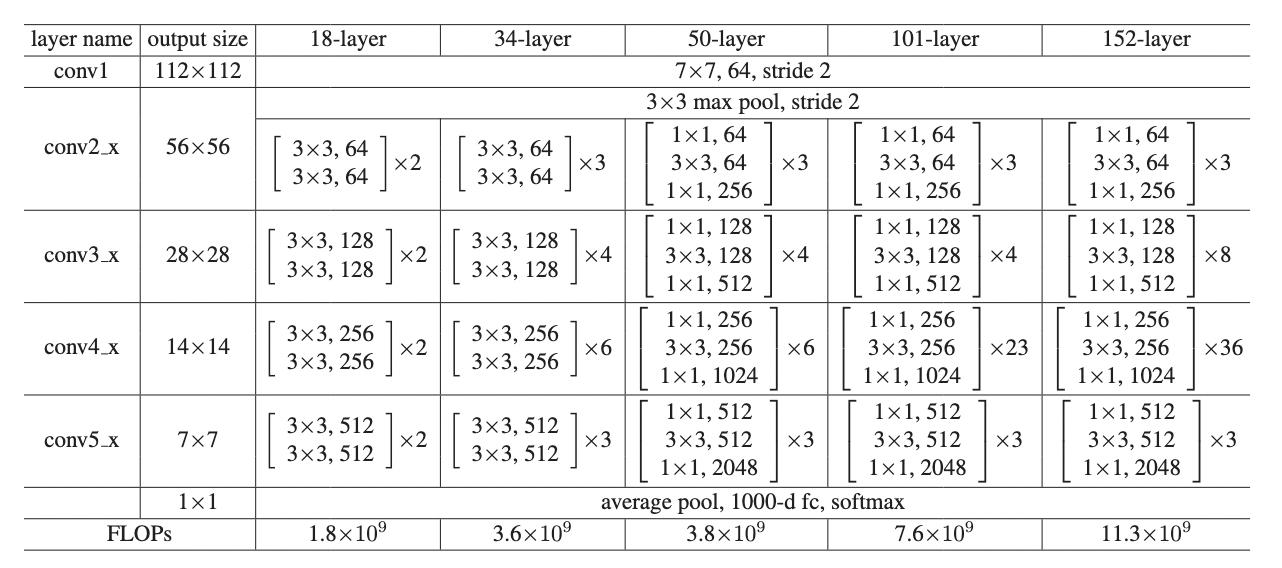
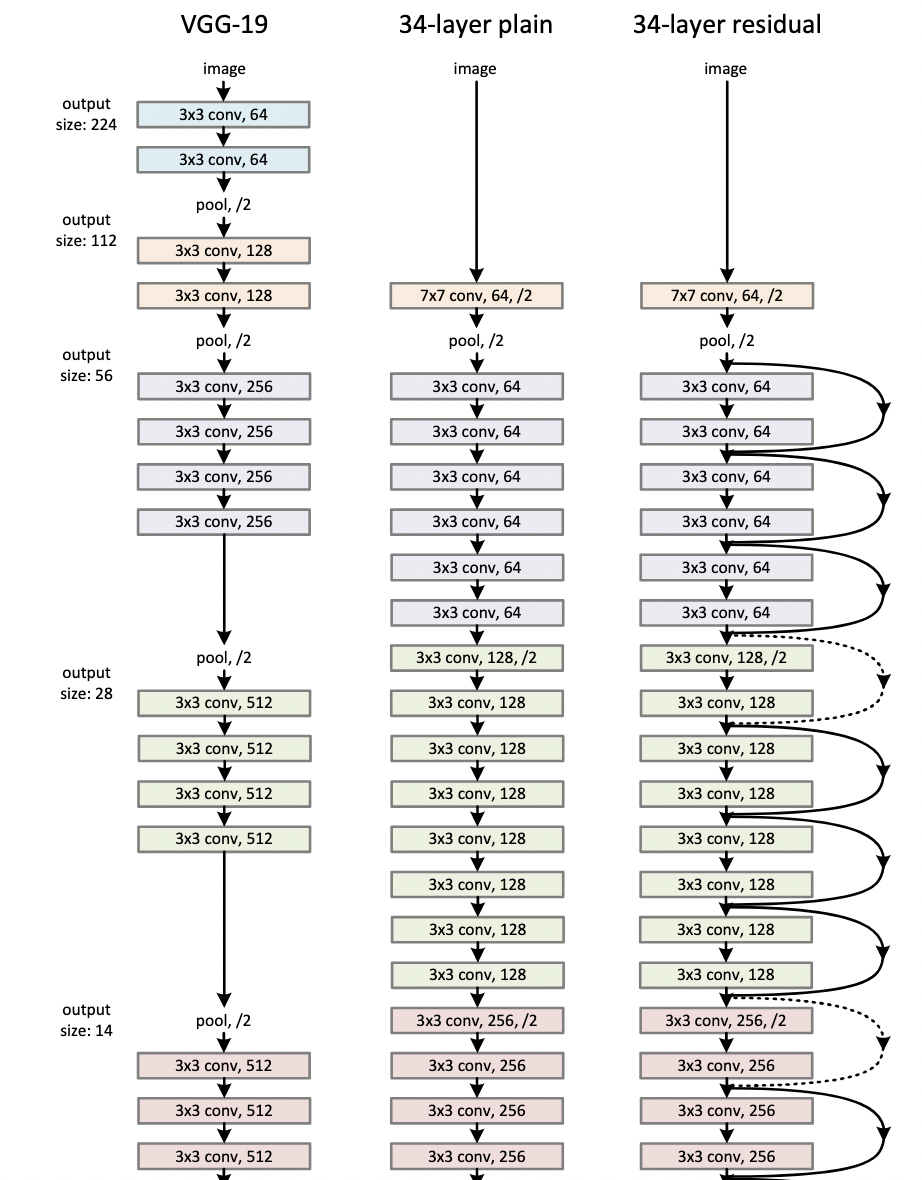
- 五个版本前面第一个卷积和池化,以及最后的全局池化和全连接都一样。主要是中间复制的块不一样。
- 34 层版本一个残差块里有两个卷积层,通道维度翻倍时,空间维度除以二。
- 50 层用 bottleneck,256 投影回 128,再投影回 512。最后通道维度做到 2048,因为比较深,可以去里面抓取更多的信息,用 2048 维向量表示图片。之前是 512。
- 通过网络架构的自动选取调超参:块个数。
- FLOPs:整个网络要计算多少个浮点数运算。卷积层的浮点运算等价于,输入的高乘宽,乘通道数,乘输出通道数,乘和的窗口的高和宽,全连接再一层。18-34翻倍,但50层架构做了改变,计算量没变。
Plain Networks
- 粗红线是34层的测试精度,细红线是训练精度,在刚开始的阶段,由于训练时用了大量数据增强,使得训练误差相对较大,测试时没有数据增强,噪音低。
- 拐点是学习率的下降,乘了 0.1,跳了两次。具体在什么地方跳是不确定的,实际上来说不应该跳太早,跳太早的话后期收敛会无力,其实还可以再往前训练一点,再跳。虽然看上去这段平了,没有做什么事情,实际上里面在做很多的微调,微笑的跳动,在宏观的数据上看不出来。多训练训练,晚一点跳是不错的选择,一开始找的方向更准一点,对后期比较好,像练内功,先积累再突破。
- 这个图主要想说明有残差连接,34层会比18要好,并且残差的34比没有的34要好。并且有残差连接,收敛会快很多。
- 核心思想:在所有超参数一定的情况下,有残差连接收敛会快,而且后期会好。
比较了输入输出不同时,怎么做残差连接
A. 补 0 B. 投影 C. 所有的连接都做投影:就算输入输出形状一样,也在连接时做 1x1 的卷积,输入输出通道数一样,做一次投影。
- 虽然 C 好一点,但是增加大量计算复杂度。B 对计算量增加不多。
怎样构建更深:Bottleneck design
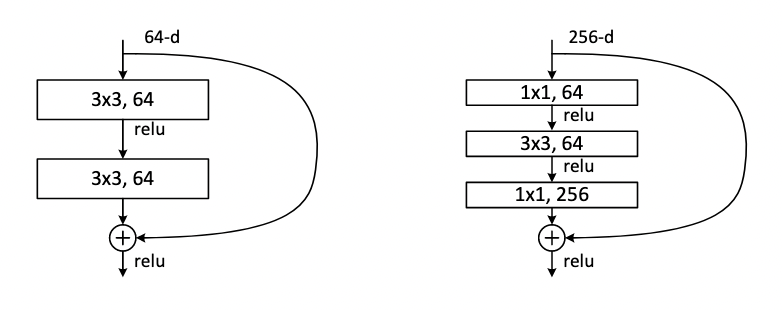
- 之前的设计,层中保持输入通道数 64 维不变。
- 瓶颈:如果要做到比较深,输入维度会比较大一点,因为很深的时候可以学到更多模式,把通道数变更大 256,计算复杂度增加是平方关系,太贵了。做法:通过 1x1 卷积,把输入维度 256 映射投影回 64,中间和原来等价,最后再投影回 256。即先对特征维度降一次维,在降维上做一个空间的东西,最后投影回去,理论计算复杂度差不多。
- 实际上 50 会比 34 贵一些,1x1 卷积在计算有效性上没有别的卷积高。现在计算资源够了,支持对层数的搜索。现在很多改版调层数。
在 CIFAR 上
- CIFAR 图片 32x32,数据集相比 ImageNet 更简单:5万例,10 类。110层最好,1202层有一些过拟合,但也不严重。
- 主要想说:残差连接要干的事情,如果在后面新加上的层不能让模型效果变好,那么因为有残差连接的存在,所以新加的层应该不会学到任何东西,靠近 0,等价于就算训练了 1000 层 ResNet,可能就前 100 层有用。
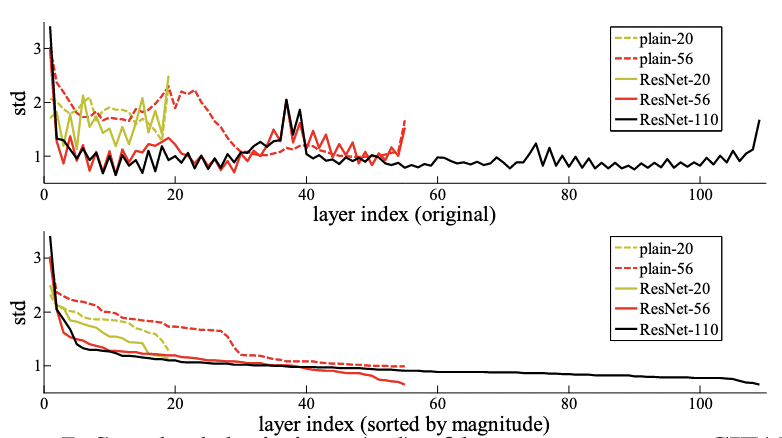
- 看一下最后那些层有没有用。如果没有学到东西,最后那些层在不加输入的时候,输出基本是 0。但这其实是两个不一样的模型,同样的超参数,在没有加残差的时候收敛是不对的,导致上图最后是没有训练好的状态,其实很难比较。
总结
- 提出了一个非常简单的方法,使得能训练更深的模型,而且整个模型的构造是非常简单的。
- 虽然现在来看,motivation 为什么做这个东西可能讲的不够深刻,但不能说实验起飞,又要给一个漂亮的理论分析,只要有一点做好就行。只要有一个亮点,大家认同,挖坑。
- 只要你的工作够厉害,是很新能启发的东西,写很多东西没说明白不要紧。