
论文阅读: BERT
Published:
读 BERT | 针对语言理解任务预训练的深度双向 Transformer
[TOC]
题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
作者:
链接:
代码:
推荐阅读:
What
- Transformer 双向的编码器表示。名字类比 ELMo 像是凑出来的,开创了 NLP 的芝麻街系列文章。
- MLM + NSP,使用无标签数据,联合左右的上下文信息(双向)。下游任务只用加一个额外的输出层。
- 区别:GPT 单向,用左边的上下文信息预测未来。ELMo 架构基于 RNN,下游任务要改架构。BERT 同 GPT 只用改最上层。
- 优点:概念简单,实验好。讲卖点时要讲明白两方面:绝对精度,相对精度(和别人比相对好了多少)。
- 对于不一样的数据集,BERT 用起来很方便。把输入表示成一对句子,拿到对应输出,最后加一个输出层。
Introduction
- 首段交代这篇论文关注的研究方向的一些上下文关系。
- 自然语言的预训练(例如用词嵌入做预训练,GPT。)包括两方面任务:
- 句子层面:建模句子之间的关系,如情绪识别。
- 词元(token)层面:实体命名识别,对每个词识别它是不是一个实体命名(人名,街道名)。
- 导言的第二段和之后,一般是摘要第一段的扩充版本。
- 使用预训练模型做特征表示,两类策略:
- 基于特征:ELMo,对每个下游任务,构造跟任务相关的网络。把于预训练好的表示(例如词嵌入),作为一个额外特征,和输入一起(因为基于 RNN)。
- 基于微调:GPT,把预训练好的模型放在下游任务时,不需要改太多。预训练好的参数在下游数据集上微调。
- 这两个方法预训练都是用相同的目标函数:单向的语言模型。给一些词,预测下一个词。
- 介绍别人方法,目的是铺垫自己的,指出别人哪些地方不好,我的方法在这一块有改进。
- 第三段讲了本文主要想法。
- 现在这些技术有局限性,特别是做预训练表征的时候。
- 主要问题是标准的语言模型是单向的,导致选架构时有局限性。例如 GPT 只能从左看到右,不是很好。
- 句子层面的分析,例如判断一个句子情绪,从右看到左也是合法的。
- 词元上的任务,例如 QA,也是能看完整个句子再选答案。
- 如果把两个方向的信息都放进来,应该可以提升这些任务性能。
- 指出了相关工作的局限性和本文提出的想法之后,讲如何解决这个问题。
- 提出了 BERT,用来减轻之前提到过的语言模型是单向的限制。
- 带掩码的 language model(MLM):受 Cloze 任务启发。每次随机选一些词元盖住,目标函数是预测那些被盖住的词(本质:完型填空)。允许看左右的信息。
- 下一个句子的预测(NSP):给两个句子,判断这两个句子在原文里是不是相邻的,还是说只是随机采样的两个句子。目的:让模型学到句子层面的信息。
- 贡献:
- 展示了双向信息的重要性。GPT 只用了单向,之前有的工作,把一个从左看到右的语言模型,和一个从右看到左简单 concat 在一起。本文在双向信息的应用上更好。
- 假如有一个比较好的预训练模型,就不用对特定任务做模型改动了。BERT 是第一个基于微调的模型,在一系列 NLP 任务取得最好成绩。
- 代码和预训练权重开源。
- (把 ELMo 双向的想法和 GPT 使用 Transformer 的东西合起来。A + B 工作,把两个东西缝在一起,或者把一个技术用来解决另外领域的问题。如果想法确实简单好用,别人愿意用就挺好的。朴实的写出来。)
相关工作
2.1. 无监督,基于特征的方法
- 词嵌入
- ELMo
2.2. 无监督,基于微调的方法
- GPT
2.3. 在有标号的数据上做迁移学习
- 视觉领域常用,在 ImageNet 上训练好模型。NLP 不理想,可能一方面,两个任务差别大,另一方面,数据量远远不够。
- BERT 和之后的一系列工作,证明了在 NLP 上面需要没有标号的大量数据集训练模型,效果比在有标号相对小数据集上训练效果更好。同样的想法慢慢被计算机视觉采用。
BERT
- 算法实现细节,先简单介绍了预训练和微调(有一些技术可能所有人都知道,但写论文时不要一笔带过,论文需要自洽):
- 预训练在无标签不同任务数据上。
- 微调时,加载预训练权重,所有权重都参与训练,用有标签数据。
- 每个下游任务会创建一个新的 BERT 模型。
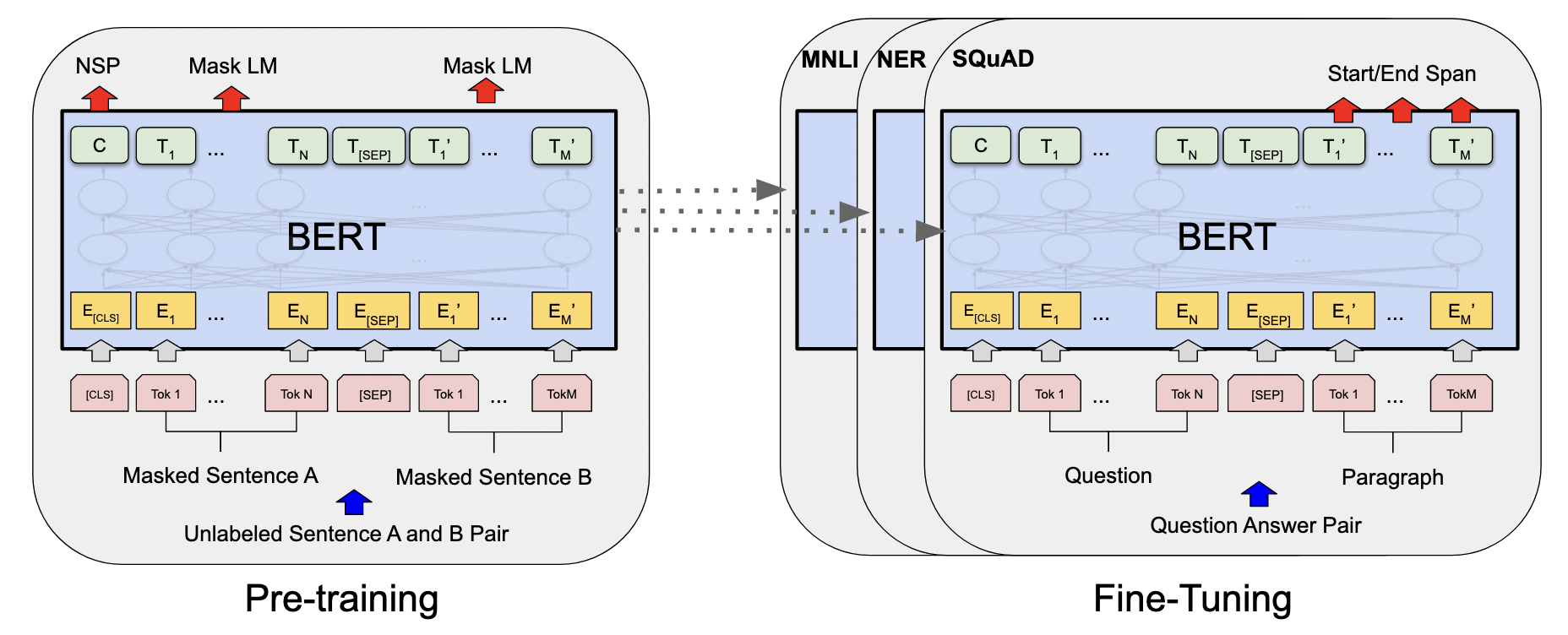
- 模型图:
- 输入无标签的句子对。
- 模型架构:
- 基于原始论文代码,多层双向的 Transformer 编码器。没做什么改动。
- 细节:调了三个参数。L:块的个数。H:隐藏层大小。A:注意力头数。
- BASE:L = 12,H = 768,A = 12,总参数:110M(1.1亿),对标 GPT。
- LARGE:L = 24,H = 1024,A = 16,总参数:340M(3.4亿),用来刷榜。
- 宽度 1024 怎么来的:BERT 模型复杂度和层数是线性关系,和宽度是平方关系。深度变成以前的两倍,在宽度上要选择一个值,使增加之后,平方是之前的两倍。(\(H_{LARGE} ^ 2 = 2 * H_{BASE} ^ 2\))
- 头的个数 16 怎么来:每个头的维度固定 64,宽度增加,头也增加。
- 怎样把 Transformer 超参数换算成可学习参数的大小:
- 参数主要来自于两块:嵌入层,Transformer 块。
- 嵌入层:本质是矩阵,输入是字典大小(30K),输出是模型宽度(H)
- Transformer 块:自注意力机制 + MLP
- 多头注意力可学习参数:4 * H ^ 2。自注意力机制本身没有可学习参数,但是对于多头注意力,会把所有进入的 QKV 分别做一次投影,每一次投影的维度等于 64。因为有各个头,头的个数 A 乘 64 等于 H。其实输入的 QKV 都有自己的投影矩阵,投影矩阵在每个头之间合并起来,所以是三个 H 乘 H 的矩阵。输出还会做一次投影,也是 H 乘 H。
- MLP 可学习参数:8 * H ^ 2。MLP 里有两个全连接层。第一层输入 H,输出 4 * H。第二层输入 4 * H,输出 H。
- 总参数(别忘了层数 L):30K * H + L * 12 * H ^ 2。
- 输入输出形式
- 对于下游任务,有些是处理一个句子,有些处理两个。为了使 BERT 能处理所有任务,输入既可以是一个句子,也可以是一个句子对。
- 具体来说,这里一个句子的意思是一段连续的文字,不一定是真正上的语义上的一段句子。
- 输入是一个序列,可以是一个句子,也可以是两个句子。(不同于 Transformer,训练时输入是一个序列对,因为编码器和解码器会分别输入一个序列。但是 BERT 只有一个编码器。)
- 序列构成:切词方法用的 WordPiece。假如按空格分词,一个词作为一个 token,因为数据量大,导致词典特别大,可能是百万级别,导致整个可学习参数都在嵌入层里。
- WordPiece 想法是,如果一个词,在整个语料里面出现概率不大,那么应该把它切开,看它的一个子序列。如果它的某一个子序列(很有可能是一个词根)出现概率比较大,就只保留这个子序列。把一个相对长的词,切成片段,这些片段是经常出现的。
- 词典大小为 30,000.
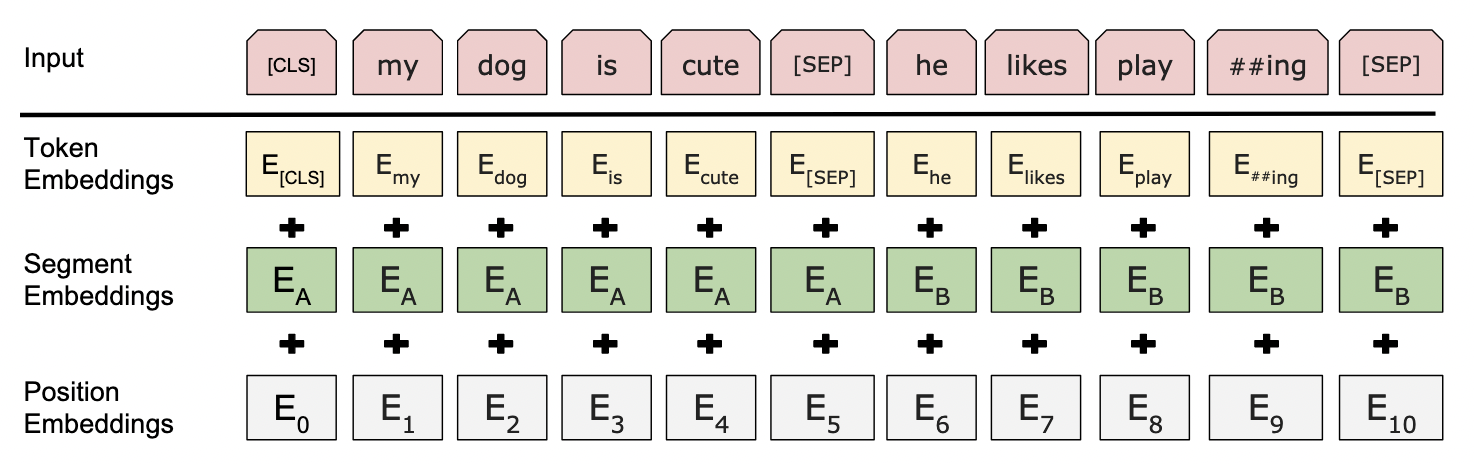
- 切好词了,怎样把两个句子放在一起:
- 序列第一个词永远是一个特殊的分类记号
[CLS]。希望它最后的输出代表整个序列的信息,例如整个句子层面。(因为用的是编码器,自注意力层里,每个词都会去看输入里面所有词的关系) - 输入是把两个句子合在一起,因为要做句子层面的分类,需要区分开这两个句子。两个办法区分:
- 句子后面放一个特殊记号
[SEP]。
- 句子后面放一个特殊记号
- 学一个嵌入层,来表示这个句子是第一个还是第二个。
- 对每个词元,最终进入 BERT 的向量表示为:词元本身的 embedding + 句子 embedding + 位置 embedding。
- 不同于原始 Transformer,BERT 句子和位置的嵌入都是可学习的。
- 序列第一个词永远是一个特殊的分类记号
- 预训练部分:
- 关键:目标函数,数据
- Mask LM:对于一个输入的 WordPiece 词元序列,有 15% 的概率随机替换成一个掩码。不处理特殊的分类和分割词元。
- 这里微调时会有问题,因为训练做掩码时会把词元替换成一个特殊的 token:
[MASK],也就是说训练数据有 15% 的词元都是MASK。但是微调时不用 MLM 这个目标函数,也就没有这个 MASK。预训练和微调看到的数据不一样,微调时真实看到的数据是没有变化的。 - 解决方法:对于这 15% 被选中去掩码的词,有 80% 的概率真的替换成
[MASK],有 10% 的概率替换成一个随机的词元(加入一些噪声),还有 10% 的概率什么都不干,只标记下这个词要用来做预测。这个比例是消融实验选的。

- 预测下一个句子:
- 预训练的第二个任务。在 QA 和自然语言推理任务里,输入都是句子对,要去理解两个句子之间的关系,而语言模型捕捉不到。
- 具体:输入序列两个句子,A 和 B。
- 有 50% 的概率,B 在原文中真的在 A 之后。(正例:
IsNext) - 还有 50% 概率,B 是随机从一个别的地方选出来的句子。(负例:
NotNext) - 加入这个目标函数能够极大提升 QA 和 NLI(自然语言推理任务)。

- 预训练数据:
- BookCorpus:8亿词,书本。
- English Wikipedia:25亿词。
- 关键是用文本层面的数据集,里面是一篇篇文章(长的连续序列),而不是随机打乱的一些句子。因为 Transformer 可以处理长序列,输入一整个文本序列,效果更好。
- 微调:
- BERT 和一些基于编码器解码器的架构有何不同:BERT 把两个句子合在一起输入编码器,所以自注意力能看两个句子。而在编-解码器架构里,句子是分开输入的,编码器一般看不到解码器的东西。
- 但是也有相应代价,不能像 Transformer 那样做机器翻译,GPT 那样生成。
- 做下游任务时,根据任务设计相关的输入输出,不改模型架构。
- 用第一个词元
[CLS]对应的输出做分类,例如:情感分析。 - 用对应那些词元的输出,做 token 层面的任务,例如:QA。
实验
- GLUE
- General Language Understanding Evaluation
- 通用语言理解评估 benchmark。包含多个数据集。
- BERT 用第一个特殊词元 CLS 最后的向量拿出来,学习一个输出层 W。
- SQuAD v1.1
- Stanford Question Answering Dataset
- QA 任务:问一个问题,给一段话,目标是把答案找出来,答案已经在给定的那段话里了。本质上就是找片段的开头和结尾。对每个词元,判断它是否为答案的开头或结尾。
- 具体:学两个向量 S 和 E,分别对应这个词元是答案开始的概率和结尾的概率。对候选第二句话里面的每个词元T,S 乘 T 再做 softmax,得到段里每个词元是答案开始的概率。同理算出是结尾的概率。
- 原文说微调时 epoch = 3(扫数据三遍),但实际上 BERT 微调时,结果非常不稳定。同样的参数数据集,训练十遍,variance 方差特别大。其实是因为 3 轮太少了,要多学习几遍才好。
- BERT 原文用的优化器是一个 Adam 的不完全版,训练很长时间没关系,但如果训练时间短,很影响,要换回 Adam 正常版来解决。
- 消融
- 消 NSP
- 消双向和 NSP
- 换架构
模型大小影响
- 假设不用 BERT 做微调,而是把 BERT 的特征作为一个静态特征输入。
- 结论:效果没微调好
- 所以如果用 BERT,应该用微调。
写作角度
- 卖点
- 写文章最好卖一个点,BERT 结论说它最大贡献是双向性。
- 但 BERT 贡献很多,如果要写双向性,要写选择双向性带来的不好是什么。因为做一个选择会得到一些,也会失去一些。
- 和 GPT 比,用编码器,机器翻译不好做,文本摘要,生成类任务不好做。
- 但分类任务在 NLP 更常见。
- 是一个完整的解决问题的思路:训练一个很深很宽的模型,在一个很大的数据集上训练好,用在很多小问题上,能通过微调提升小数据上的性能。
总结
- Encoder only,只做 padding mask。
- MLM:15% –> 8:1:1
- NSP:IsNext or NotNext
- 输入是成对句子
- 特殊词元:CLS,SEP,MASK
- 把 ELMo 双向的想法和 GPT 使用 Transformer 的东西合起来。A + B 工作,把两个东西缝在一起,或者把一个技术用来解决另外领域的问题。如果想法确实简单好用,别人愿意用就挺好的。朴实的写出来。)