
论文阅读: AlexNet
Published:
读 AlexNet |
[TOC]
题目:
作者:
链接:
代码:
推荐阅读:
读前
- 再经典的文章也有时代局限性,保留哪些精髓。
- 三个 dirty trick:图片增强,ReLU,Dropout。
- 对工作的欣赏在于,这个工作揭示了什么深刻见解:对这个世界或模型的新理解,解释一点东西出来,为什么效果好,哪些地方效果好。
第一遍
摘要
- 做了什么,效果多好。
- 五个卷积,MaxPooling,三个全连接,最后一个Softmax。
- 用了 GPU 实现。
- 为了减少过拟合,用了正则化:Dropout。
- 比第二好了多少。
- 像技术报告,但是结果好。
直接跳到最后:讨论
- 如果去掉一个卷积层,性能会下降,所以深度很重要。
- 结论没错,但是拿掉一层,性能下降,也可能是因为参数没设好,搜参搜的不够。实际上把中间参数变一变还是能达到。
- 现在看来,更完整的结论是,深读很重要,宽度也相对重要。像拍照一样,高宽比很重要。
- 为了简化实验,没有用无监督预训练(用一些没有标号的数据预热,把权重训练到相对比较好的范围,再往下训练)。
- 在这之前,深度学习的目的是,通过训练一个非常大的神经网络,在没有标号的数据上,把里面内在的结构抽取出来。因为人类学东西很多时候不一定知道真实答案是什么,读书百遍,其义自现。追求的是无监督学习,觉得 AlexNet 走歪了,后来 BERT 和 GAN 拉回来(给我数据,但是不要告诉我标号,我真的能去从中间理解)。
- 最后,想在 video 上做。视频里面有一些时序信息,帮助理解在空间的图片信息。问题:计算量,版权。
看重要的图表和公式

- 右图把倒数第二层的输出拿出来,得到一个长向量,看一下和这个向量上最近的那些图片。
- 实际是最重要的一个结果:深度神经网络训练出来最后那个向量,在语义空间里的表示特别好,相似的图片真的会放在一起,是一个非常好的特征。非常适合后续机器学习,用一个简单的分类器就能做特别好。
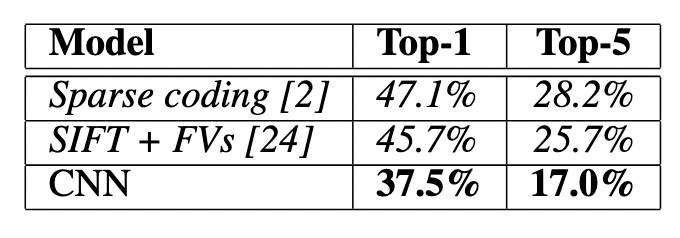
- 和别人结果的对比。卖点是结果好。
- 第一遍通常能看懂的是,一些实验的结果图。
- 第一遍读下来知道,这篇文章结果特别好,是用神经网络做的。
- 具体为什么好,具体怎么做的呢?决定要不要往下读。
第二遍
- 主要目的:知道细节在干什么,了解作者怎么想的,怎么表述。
- 每篇文章都有自己的观点,每个作者对世界的认识有一定角度。感受作者对整个问题的看法。
- 写文章的时候,作者通常会把自己所有想的东西一股脑拍在文章上面,掏空。比读别的博客和简单介绍信息量更多。
- 对于研究者最重要的事情:需要读很多文章,总结不同的优秀研究者对这个世界的认识,然后形成自己独特的观点。每个人都需要有自己的观点,观点不对没关系,一定要有自己独特的观点,才能不一样。如果和别人的观点都一样,那么对这个世界的贡献就没那么多了。
- AlexNet 对技术的选择和描述,从现在的角度看,其实里面绝大部分观点是错的。有大量细节,从现在角度来讲是没有必要的,是过度的 engineering。
介绍
- 一篇论文的第一段,通常是讲一个故事:我们在做什么研究,哪个方向,有什么东西,为什么很重要。
- 本文:要做物体识别,也是图片分类。为了提升性能,要收集更大数据集,训练更厉害的模型,用更好的技术避免过拟合。这也是这篇文章之前,在大数据年代关心的。
- 过拟合代表了深度学习的派别:用很大的模型,通过正则避免过拟合。但是从现在的观点来看,正则好像没那么重要。最关键的是整个神经网络的设计,使得很大的神经网络,在没有很好的正则情况下也能训练出来。
- 第二段只提 CNN,不提别人的算法,视角窄了。和别的方向做一个稍微公平的介绍。
- 第三段说 CNN 虽然很好,但是训练不动,但现在有GPU了。
- 第四段讲本文贡献。大的数据集,大的模型,然后避免过拟合。用了一些新的没用过的东西,可以提高性能,降低过拟合。新的技术是比较有意思的,有启发性。
- 从一作角度讲,有很大工程量,但是从一个研究工作的角度,能存下来的很难是工程性的细节,还得是技术上。
数据集
- ImageNet 1500万数据,2万类。竞赛用的子集,1000类,每一类1000张图片。
- 2010年公开了测试集,2012年没公开。
- 图片裁剪:先按短边降到 256,然后把长边按中心裁到 256。
- 重点:没有做任何预处理,就是剪裁一下,减去均值。输入是 raw RGB 的像素值。
- 在当时通常做法是先把特征抽出来,抽SIFT。但是这个工作不用抽特征,是在原始像素上做的。之后的工作卖点主要是 end to end。原始的图片,文本直接进去,不用做任何特征提取,神经网络能直接做。(历史局限性,没有把亮点写出来)
- 简单有效的东西是能够持久的。
架构
- ReLU 非线性
- 一个东西能流行,标题,名字很重要
- epoch:扫多少遍数据
- 现在的角度来看:也没有比别的快多少,纯粹因为简单。简单就是胜利。
- 多 GPU 训练
- 第二遍读,工程先忽略
- 归一化
- 这个现在已经不用了
- 重叠池化
- 标记一下什么是池化。
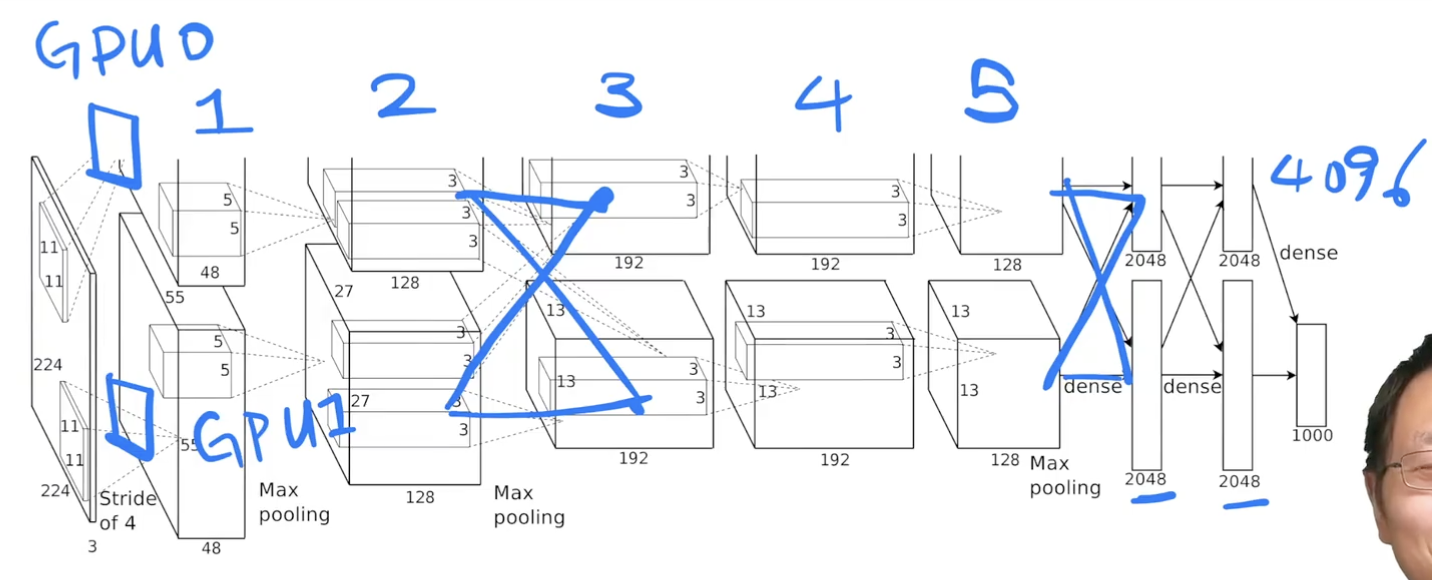
- 总体架构
- 5卷积,3全连接,softmax
- 输入 224x224x3,第一个卷积层 96个大小为11x11x3的卷积核,步长4.
- 模型横着切开,每个GPU有48个卷积核。前两个卷积层在各自GPU上做,没有通讯。
- 第三个卷积层也会去看对方,拿到第二个卷积层在 GPU0 和 GPU1 上的输出,在输出通道维度合并,卷积核大小为3x3x256.
- 第四五个卷积层是各做各的。
- 输入本来是很扁很宽的图片,把高宽边小,深度增加。随着网络增加,慢慢把空间信息压缩。224x224 压缩到最后 13x13,认为最后的每一个像素可以代表前面一大块的像素。通道数慢慢增加:可以认为每个通道是去看一种特定的模式。整体是在压缩空间信息,但是语义空间慢慢增加。
- 全连接再次通讯。输入是每个GPU第五个卷积的输出合并起来。每张卡 2048 的全连接,最后拼回成一个 4096 长的向量。
- 这个长为 4096 的向量很好的能够抓住语义信息。如果两个图片的 4096 的向量特别相近,这两个图片很有可能是同一个物体的图片。
- 深度神经网络的精髓:输入一张图片,通过卷积和全连接做特征提取,最后压缩成一个向量,这个向量能够表示中间的语义信息,变成了一个机器能懂的东西。机器学习就是一个知识压缩的过程。原始数据通过模型压缩成一个机器能识别的向量
- 近些年的大语言模型为了能训练,又开始切模型了。
如何降低过拟合
- 我训练了一个很大的神经网络,要避免过拟合,应该怎么办。
- 过拟合:给你一些题,你就把它背下来,根本没有理解题是在干什么,所以考试的时候肯定考不好。(泛化性差,过度拟合了特定数据)
- 数据增强:
- 在 256x256 里随机扣一块 224x224 的区域,相当于数据量变为 2048 倍。但实际上不能这么算,因为扣下来的东西长得都差不多。
- 在 RGB 通道上做改变。先用 PCA,每次图片和原始的颜色会不一样。
- 数据增强在 CPU 跑,模型在 GPU。在现在看,因为GPU发展速度比CPU快,数据增强容易成为性能瓶颈。有可能要搬到 GPU 上,或者用很好的 C++ 来实现。
- Dropout
- model ensemble 很贵。
- 随机把一些隐藏层的输出用 50% 的概率设为 0,相当于每次得到一个新的模型,但这些模型之间权重共享。
- 后来大家发现 Dropout 其实好像也不是在做模型的融合,更多的是就把它看成一个正则项,但是无法构造出一个跟它相等的一个正则的东西。在现行模型上等价一个 L2 正则项。
- 放到了前面两层全连接上。最后一层是输出,中间两个很大的 4096 全连接是模型的一大瓶颈。设计的缺陷,导致模型很大,放不进gpu,还要用dropout避免过拟合。
- 现在 CNN 的设计通常不用那么大的全连接,导致dropout也不那么重要。而且gpu内存也不那么吃紧了,导致由模型设计决定。
- 反过来讲,dropout在全连接上还是非常有用,在attention部分用的多。
模型如何训练
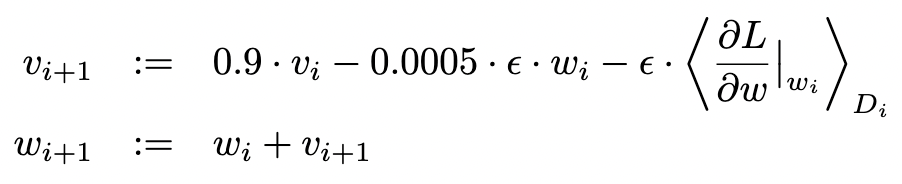
- SGD
- 当年觉得难调参,后来发现SGD里的噪音对模型的泛化性有好处。
- 发现用了一点的 weight decay 是非常重要的。机器学习主流叫 L2 regularization,神经网络喜欢叫wd,等价的。不是加在模型上,而是加在优化算法上。
- momentum:当优化表面非常不平滑时,这个冲量使得你不要被当下的梯度太多误导,可以保持一个冲量,从过去那个方向,沿着一个比较平缓的方向往前走。不容易掉到坑里去。
- momentum 项 = 0.9 * 过去的动量 - weight_decay - 梯度
# Momentum update v = mu * v - learning_rate * dx # integrate velocity x += v # integrate position - 其中 v 初始化为 0,mu 是动量,值为 0.9,物理意义和摩擦系数一致,该变量抑制速度并降低系统动能,使该点在山脚停下来。
- 权重初始化
- 均值为 0,方差为 0.01 的高斯随机变量。
- 方差 0.01 怎么来的:这个值不错,不大不小,对很多网络适用。
- BERT 初始方差用 0.02
- Biases:卷积的第二,四,五层,和全连接初始化为 1,剩下的初始化为 0。
- 偏移本质上,如果数据比较平衡,应当初始化为 0,效果也不差,也不需要调参。

- 学习率
- 0.01 开始,如果验证误差不降了,再手动乘 0.1,即降低十倍。90 个 epoch,也是就扫了数据90遍。每一遍用的是 ImageNet 不完整的 120 万张图片。调一次参五六天。
- ResNet:训练 120 epoch,每 30 轮下降 0.1
- 另外一种主流做法:前面训练更长一点,60或100轮,后面再下降。
- 规则性下降现在很少用了。为什么要降 10 倍,什么时候下降,很难控制。初始 0.1 怎么选也比较尴尬,一开始不能选太大,容易炸掉,但是选太小也训练不动。
- 现在用更平滑的曲线下降学习率。例如 cos。
- 现在主流做法:学习率从 0 开始,慢慢线性增大,然后再用 cos 函数下降。调参更少。
实验
- 很多读论文的时候,实验部分相对来说没那么重要,关心的是实验效果。但是具体实验怎么做的,除非是领域专家,扫一眼大概能懂。如果是刚来这个领域,不用太关心细节。
- 只有在要重复它的实验,或审论文,或是领域专家的时候,会大概看一下实验。
- 最后报告了在完整 ImageNet 890 万张图片,10184 类上的实验。完整数据的预训练效果应该好很多,模型质量更好。
- 把 2010 年(可获取)的作为验证集,2012 年(不可获取)作为测试集。
看一下这个网络会是什么样子

- 奇怪的现象:
- 因为是在两个 gpu 上训练的,如果输出通道是 256 个,分成了两个 128,每个通道可以认为是识别了图像里一些特定的模式。
- 发现 GPU 1 的通道基本和颜色无关,GPU 2 和颜色相关。
- 看每个通道在干嘛

- 可解释性
- 看一下每个 feature activation,就是每个卷积层,全连接的输出在干什么。 例如倒数第二层的 4096 维向量。如果两张图的 4096 向量的欧式距离相似,这两张图在高维语义也相似。
- 最左列是测试图像,右6列来自训练集,和测试的 4096 向量有最短欧式距离。
- 可以看到,在像素级别上,右侧训练图和最左测试的query图之间。L2的距离并不相近,例如同种动物,但姿势并不相同。因此这种检索应该是语义相似。
- 后续是说,这种 4096 向量上的欧式距离计算并不高效,训练一个自编码器,把 4096 向量压缩成二进制编码,表示为二维空间坐标更高效(t-SNE)。这比直接在原始像素上用自编码器要好。
- 神经网络到底在学什么
- 虽然很多时候不知道在学什么,但是有一些神经元还是很有对应性的。底层的神经元学到了一些比较局部的信息,比如纹理,方向。偏上学到的更多是一些比较全局点的,比如说,这是一个人的头,手,这是个动物。
- 但是相对简单一点的机器学习模型来说,神经网络现在大家仍然不知道到底在学什么。可解释性,公平性,偏移。到底用什么做决策。