
cs231n_cnn_2
Published:
CS231n_cnn: 2. Visualizing what ConvNets learn
太长不看
本节内容:卷积网络的可视化和可解释性
- 可视化第一个卷积层前向传播的激活图,随着训练变得稀疏和局部化。
- 可视化第一个卷积层的滤波器权重,应当平滑无噪声,否则考虑训练时间不够,或正则强度低导致过拟合。
- 可视化图像整个数据集和某些神经元的激活值,解释该神经元的具体功能。例如某个神经元负责文本,则和该神经元相关的图像更能使其激活。
- 可视化整个样本空间:t-SNE 对图像做二维嵌入,对每个样本执行。
- 可视化感兴趣类别的概率热力图:通过遮挡,将图像一个patch置0,滑动该块遍历图像。
- 可视化梯度
- ReLU 神经元没有语义,可以看成是图像在特征表示空间中的基础向量,相当于待定坐标轴,非线性就是在表示空间中,以新的坐标轴描述图像。
- 卷积网络本质:将图像逐渐转换到某个表示形式,在这种表示下,类别是可以被线性分类器分开的。t-SNE 可视化了整个数据集样本的特征空间,语义上相近的样本空间距离也更近,物以类聚。
1. 可视化激活图和第一层的权重
1. Layer Activations
- 最直接的可视化方式:看看前向传播时的网络激活。对于ReLU网络,激活通常一开始相对模糊和密集,随着训练变得稀疏和局部化。
- 这里有个小坑:对于许多不同的输入,某些激活图可能全部为 0,意味着 dead filters,也可能由于学习率太高。

激活图可视化:第一个卷积层,第五个卷积层。格子里的激活图对应某个滤波器。可以看到激活图是稀疏的,大部分是0,且局部。
2. Conv/FC Filters
- 第二常见的策略是可视化权重。第一个卷积层解释性最强,因为直接对应原始图像。
- 已经训练好的网络通常显示清晰和平滑的滤波器,没有噪声。如果有噪声, k可能表明网络训练时间不够,或正则化强度低,导致过拟合。

滤波器可视化:第一个卷积层,第二个卷积层。AlexNet的灰度,颜色特征分别聚集,因为是两个分开处理的流,一个流建立了高频灰度特征,另一个低频颜色特征。第二层不太能解释。
2. 检索最能激活神经元的图像
- 把一个很大数据集的图像喂给网络,跟踪是哪些图像最能激活该神经元。可视化这些图像,理解该神经元在感受野中寻找什么。

AlexNet第五个池化层的最大激活图。某些神经元对上半身、文本,镜面高光有反应。
- 该方法的问题是,ReLU 神经元自身不具有语义,那ReLU关注哪部分呢。相反,可以将 ReLU 神经元视为图像在特征表示空间中的基础向量,相当于坐标轴,非线性就是在表示空间中,以新的坐标轴描述图像。换句话说,这种可视化在展示特征表示的边缘,沿着轴的就代表和滤波器权重相关。这也可以从以下事实中看出:ConvNet 中的神经元在输入空间上线性运行,因此该空间的任何旋转都没有用。
3. t-SNE Embedding
卷积网络本质上:将图像逐渐转换到一种表示形式,在这种表示下,类别是可以被线性分类器分开的。
ConvNets can be interpreted as gradually transforming the images into a representation in which the classes are separable by a linear classifier.通过将图像嵌入到二维,来大致了解整个隐空间的结构,此时不同样本之间的低维表示和高维表示基本等距离。很多嵌入方法将高维向量嵌入到低维,同时保留了点之间的 pairwise distance。t-SNE是其中效果最好的。
可以想像,对整个数据集的样本空间做可视化,应表现为物以类聚。
如何生成 embedding:用卷积网络提取图像为 CNN 编码,例如 AlexNet,最终分类器前,是 4096 维的向量,要包括 ReLU 非线性。对于每个图像,将这个向量通过 t-SNE 降到二维。可视化如图:

基于图像 CNN code 的 t-SNE 嵌入可视化。
- 靠近的图像在CNN表示空间里也同样接近,表明CNN认为这些图像非常相似。
- 注意,这种相似性通常是和类别、语义相关,而不是像素颜色。
4. 遮挡图像的某些部分
假如卷积网络把一个图像分类为狗,怎么确保网络实际上在捕捉图像中的狗,而不是背景或其他杂项?可以概括为,模型根据图像的哪些部分得出分类结果呢。
将感兴趣类别(狗)的概率用遮挡对象位置的函数来描绘:遍历图像,将某个 patch 置 0,观察该类别的概率。用二维的热力图可视化概率。
可以想像,如果遮挡的这部分和正确类别无关,不影响分类结果,则依旧可以预测出感兴趣的类别,即该类别的概率很大,热力图上为红。反之,如果遮挡到影响分类的部分,热力图为蓝。
可视化表现为,感兴趣类别应为蓝,无关区域为红。
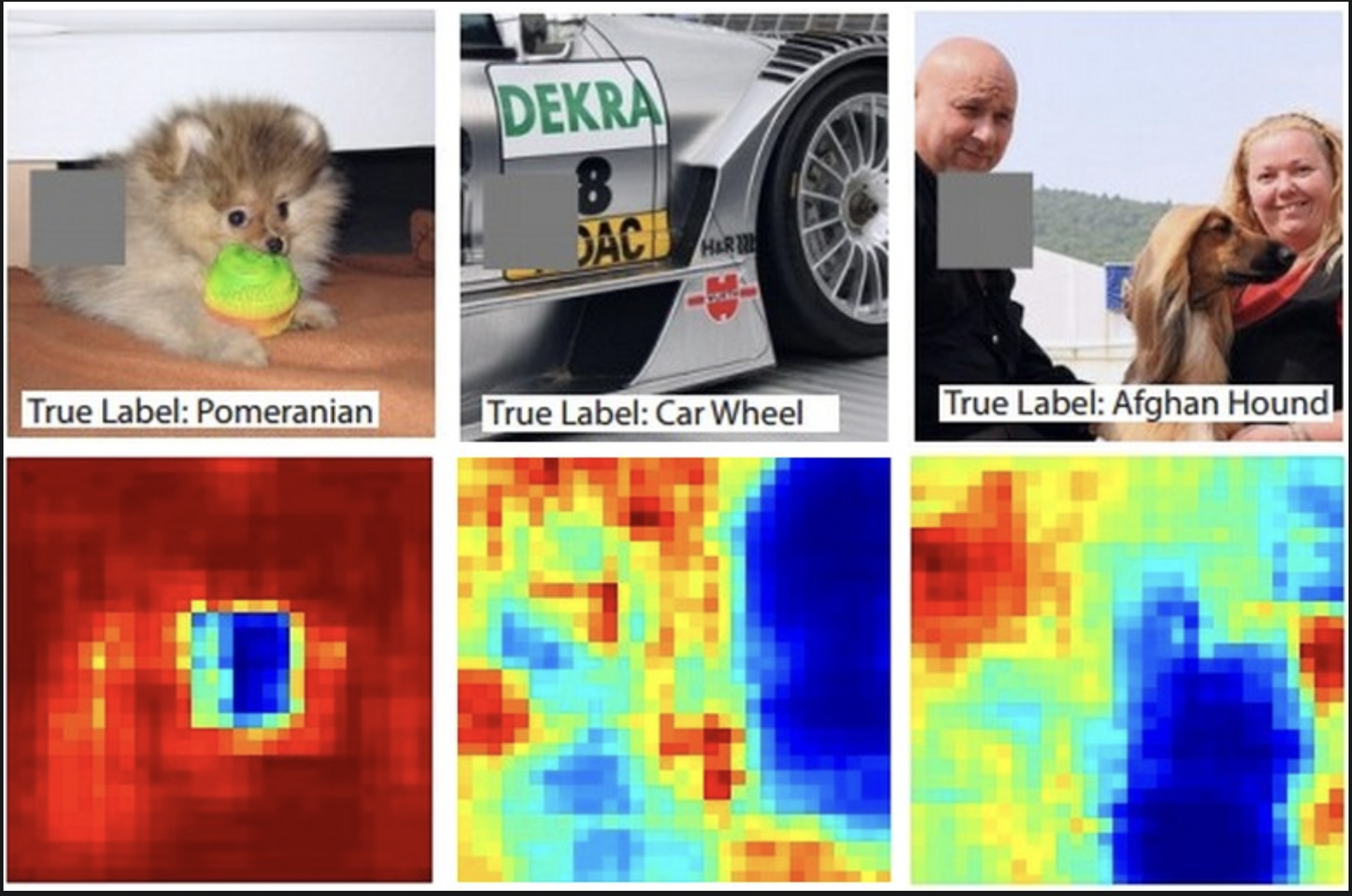
遮挡部分用灰色表示,在滑动遮挡的过程中,记录正确类别的概率,可视化为热力图。
- 例如,最左侧的图,当遮挡部分盖住狗的脸时,类别概率很低。可以认为狗的面部是导致分类分数较高的主要原因。
- 相反的,将图像其他部分置0,对分类几乎没有影响。