
论文阅读: DeepSeek-R1
Published:
读 DeepSeek-R1 | 通过强化学习激励大语言模型的推理能力
[TOC]
题目:Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
作者:
链接:
代码:
推荐阅读:

What:
- 太长不看:在有监督微调后,通过 RL 提高模型推理能力。
- R1-Zero:没有 SFT,直接 RL。
- R1:SFT + RL + cold-start data
- 第一代推理模型,R1-Zero 通过大规模强化学习(RL)训练,无需有监督微调(SFT)作为初始步骤,表现出了显著的推理能力。
- 然而,R1-Zero 遭遇了 poor readability, 和 language mixing 方面的挑战。
- 为了解决上述问题,进一步提高性能,R1 在强化学习之前结合了多阶段训练和 cold-start data。
2. Approach
2.1. Overview
- 过去的工作严重依赖大量有监督数据来提高模型性能。本研究表明,不使用有监督微调(SFT)作为一个 cold start,通过大规模强化学习(RL)也可以显著提高模型性能。
- 通过包含少量的 cold-start 数据,可以进一步提高性能。
- 以下部分包括:
- R1-Zero:不含任何 SFT 数据,直接在原始模型上用 RL。
- R1:先用数千个长思维链(CoT)微调,然后从这个 checkpoint 开始用 RL。
- 把 R1 的推理能力蒸馏到小模型中。
2.2. R1-Zero: Reinforcement Learning on the Base Model
- 过去的工作表明,强化学习在推理任务中很有效。但这些工作严重依赖有监督数据,收集耗时。
- 本节探讨了LLMs在无标签数据情况下建立推理能力的潜力,重点关注通过纯粹的强化学习自我进化。
- GRPO
- Rule-based reward modeling
- think template
2.2.1. Reinforcement Learning Algorithm
- Group Relative Policy Optimization
- 为了节省 RL 的训练成本。GRPO 舍弃了和policy策略模型大小相同的 critic 评论模型,转而通过 group scores 评估 baseline。
- 具体来说,对于每个问题 q,GRPO 从旧策略模型 πθold 中 sample 一组输出 {o1, o2, · · · , oG},然后通过最大化以下目标,优化策略模型 πθ。
2.2.2. Reward Modeling
- 奖励是训练信号的来源,决定了RL的优化方向。采用了基于规则的奖励系统:
- Accuracy rewards:评估回复是否正确。例如,对于具有确定性结果的数学问题,模型需要以指定格式(例如在框里)提供最终回答。对于LeetCode问题,可以使用编译器根据预定义的测试样例生成反馈。
- Format rewards:强制模型将思考过程放在
<think>和</think>tags之间。
- 没有使用结果或过程神经奖励模型,因为神经奖励模型在大规模RL过程中可能受到 reward hacking,重新训练奖励模型需要额外资源,并且复杂化整个训练 流程 pipeline。
2.2.3. Training Template

设计了一个简单的模版,指导 base model 遵守这种 specified instructions。模板要求首先生成一个推理过程,然后是最终回答。
有意识地将约束限制在这种结构格式上,从而避免任何 content- specific 的 biases,例如强制进行反思推理或推行特定的问题解决策略,以确保可以在 RL 过程中准确观察到模型的自然进展。
2.2.4. R1-Zero 的一些实验表现
Performance
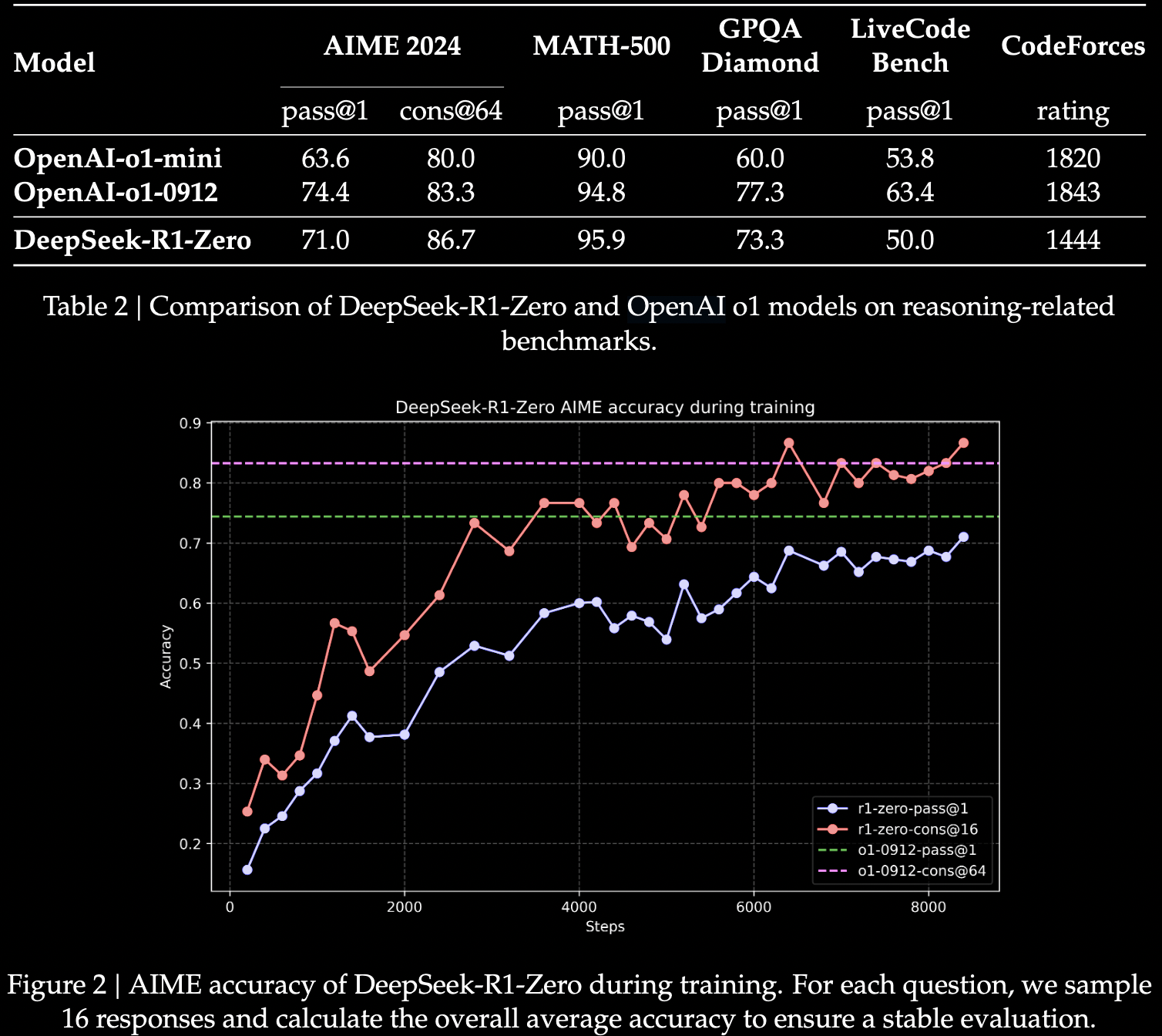
- 在 AIME 2024 上的 average pass@1 score 从最初的 15.6% 到 71.0%。通过 majority voting 可进一步提高到 86.7%。
- 表明无需SFT,仅RL的学习和泛化能力,和在推理任务的潜力。
Self-evolution Process
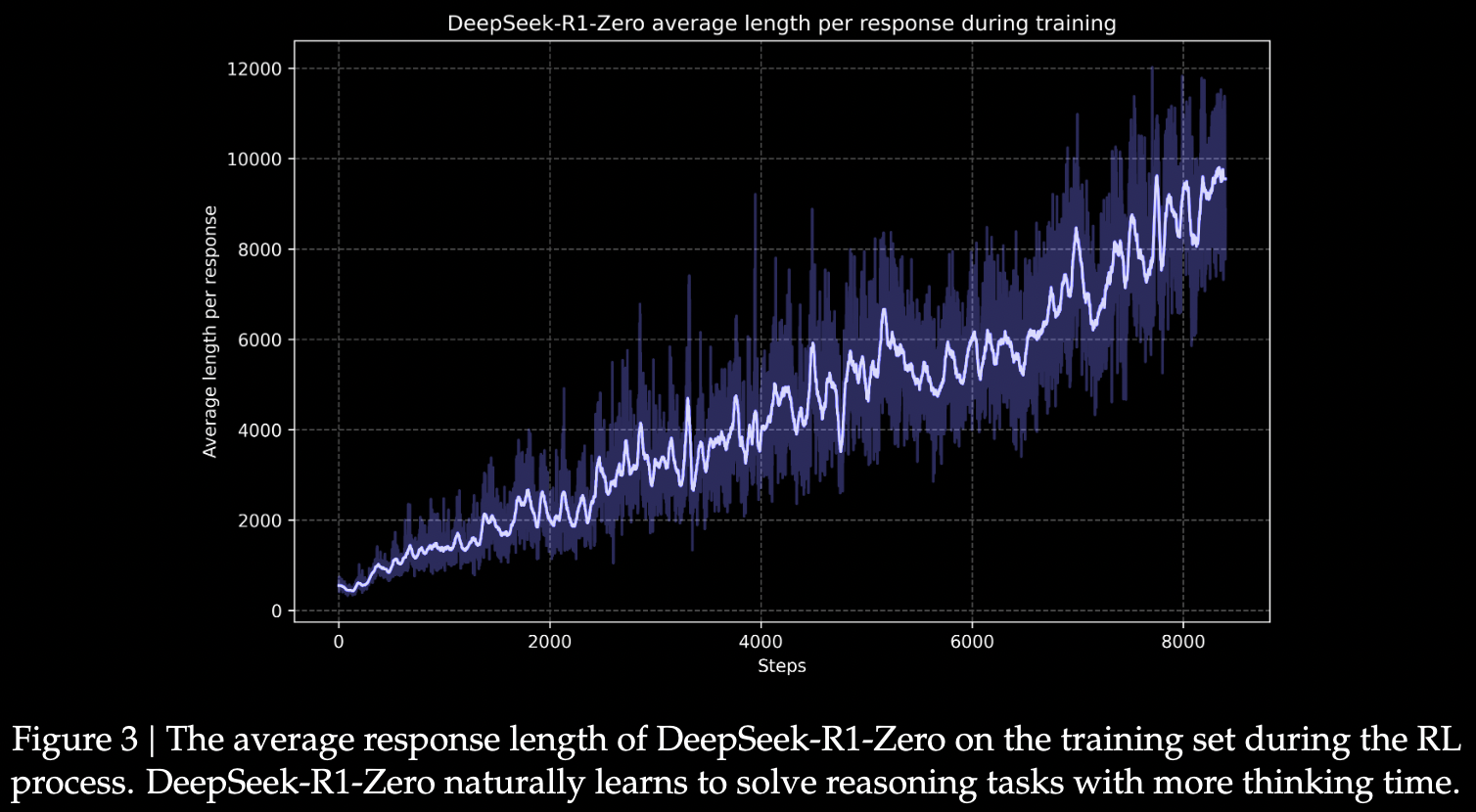
- 自我进化过程
- 直接将 RL 用于 base model,用更长的思考时间解决推理。
- 是模型的内在进步,并非外部调整。通过利用扩展的 test-time 计算,自然的获得了解决复杂推理任务的能力。
- 计算范围从几百扩展到几千个 reasoning token,使模型更深入完善思维过程。
- 随着 test-time computation 的增加,涌现出复杂行为。
- 例如反思(模型重新审视和评估先前步骤),探索替代方法,都会自发出现。
- 这些行为没有显式编程,而是模型和 RL 环境交互的结果。
Aha Moment

- 顿悟时刻
- 发生在模型的中间版本,在这个阶段,模型通过重新评估初始方法,学会为问题分配更多的思考时间。
- 证明了模型不断增强的推理能力,也是 RL 导致的意想不到的复杂结果。
- RL 的 power and beauty:我们不是明确地教模型如何解决问题,而是简单提供正确的激励,然后模型自发构建先进的解决问题策略。
- RL 可能在人工系统中解锁新的智能水平,未来更加 autonomous 和 adaptive 的 models。
R1-Zero 的缺点
- poor readability
- language mixing
2.3. R1: Reinforcement Learning with Cold Start
- 受 R1-Zero 的启发:通过少量高质量数据作为 cold start,能否提高推理性能,加速收敛?
- 如何训练一个用户友好的模型,不仅生成清晰连贯的思维链 (CoT),还表现出强大的 general 通用能力?
- 训练 R1 的 pipeline,四步走:
2.3.1. Cold Start
- 防止 base model 出现 RL 训练早期的不稳定 cold start 阶段,R1 构建和收集了少量长思维链数据,将模型作为初始 RL actor 进行微调。
- 为了收集这些数据,探索了以下方法:
- 例:少样本提示的长思维链。直接 prompting 提示模型通过反思和验证生成详细回答,然后以可读格式收集 R1-Zero 的输出,通过人工标注,用后处理的方式精炼结果。
- 收集了数千条冷启动数据,微调 V3-Base 作为 RL 的起点。和 R1-Zero 相比,冷启动的优势在于:
- 可读性:R1-Zero 的内容通常不适合阅读,回答可能混合多种语言,或缺少高亮的 markdown 格式。在创建 R1 的冷启动数据时,设计了一个可读的格式,在每个 response 的末尾会包括一个 summary,并过滤掉了对读者不友好的回复。输出格式:
|special_token|<reasoning_process>|special_token|<summary>。reasoning process 是 query 的思维链,summary 是对推理结果的总结。 - Potential:通过使用人类先验(priors)设计冷启动数据格式,性能比 R1-Zero 更好。
We believe the iterative training is a better way for reasoning models.
- 可读性:R1-Zero 的内容通常不适合阅读,回答可能混合多种语言,或缺少高亮的 markdown 格式。在创建 R1 的冷启动数据时,设计了一个可读的格式,在每个 response 的末尾会包括一个 summary,并过滤掉了对读者不友好的回复。输出格式:
2.3.2. 面向推理的强化学习
- 用 cold-start data 微调了 V3-Base 后,用和 R1-Zero 相同的大规模强化学习过程来训练。此阶段侧重于增强模型推理能力,尤其是强推理任务,例如coding,数学,科学,逻辑推理,涉及定义明确的问题和清晰的解决方案。
- 训练过程中,CoT 经常表现出 language mixing,尤其是当 RL prompts 涉及多种语言时。为了缓解语言混合问题,在 RL 训练期间引入了语言一致性奖励,计算目标语言的单词在思维链中的比例。
- 尽管消融实验表明,这种对齐会导致模型的性能略有下降,但这种 reward 和人类偏好一致,更有可读性。
- 推理任务的准确率和语言一致性的奖励直接相加,得到最终 reward。
- 在微调模型上用 RL 训练,直到在推理任务上收敛。
2.3.3. Rejection Sampling and Supervised Fine-Tuning
- 推理 RL 收敛时,从 checkpoint 收集 SFT 数据,用于下一轮。
- 初始 cold-start 数据主要关注推理。而这个阶段整合了其他领域的数据,用来增强模型在写作,角色扮演,和其他通用任务的能力。
- 使用以下约 800k 个样本的精选数据集对 V3-Base 进行了 2 个 epochs 的微调。
Reasoning data
- 在 RL 训练的 ckpt 执行 rejection sampling,得到推理 prompt 并生成推理轨迹。
- 在上一阶段,只包含了能用 rule-based rewards 进行评估的数据。
- 但在这个阶段,通过整合额外的数据,扩展数据集。用 generative reward model,将 gt 和 prediction 输入到 V3 中进行 judgment。
- 由于模型输出有时混乱,难以阅读。因此过滤掉了混合的语言,长释义,和代码块的思维链。
- 对于每个 prompt,采样多个回复,只保留正确的回复。总共收集了约 600k 个推理相关的训练样本。
Non-Reasoning data
- 非推理数据,例如写作,事实QA,自我认知,翻译,采用了 V3 的 pipeline,复用了部分 V3 的监督微调数据集。
- 对于某些非推理任务,调用 V3 生成一个潜在的思维链,然后通过提示 prompting 来回答问题。
- 对于简单的 query,例如 hello,不在回复中提供 CoT。
- 最终收集了约 200k 个与推理无关的训练样本。
2.3.4. Reinforcement Learning for all Scenarios
- 二级强化学习,和人类偏好对齐,提高有用性和无害性,同时完善推理能力。具体:用奖励信号和各种 prompt distribution 的组合训练模型。
- 推理数据:同 R1-Zero,基于规则的奖励。指导数学,代码,逻辑推理等领域的学习。
- 一般数据:用奖励模型,捕捉复杂和细微场景中的人类偏好。
- 基于 V3 的 pipeline,采用类似的 preference pairs 和 training prompts 的 distribution。
- helpfulness:只关注最终 summary 是否有用,同时最大限度减少对推理过程的干扰。
- harmlessness:评估整个回复,包括推理过程和总结,识别并减轻生成过程中的任何风险。 这种奖励信号和多样数据分布的结合,使得模型有出色推理能力,同时优先考虑有用性和无害性。