
论文阅读: Dual-Path Convolutional Image-Text Embedding
Published:
读 CVPR17 | TOMM 用CNN分100,000类图像
题目:Dual-Path Convolutional Image-Text Embedding
作者:
链接:http://arxiv.org/abs/1711.05535
代码:https://github.com/layumi/Image-Text-Embedding
推荐阅读: https://zhuanlan.zhihu.com/p/33163432
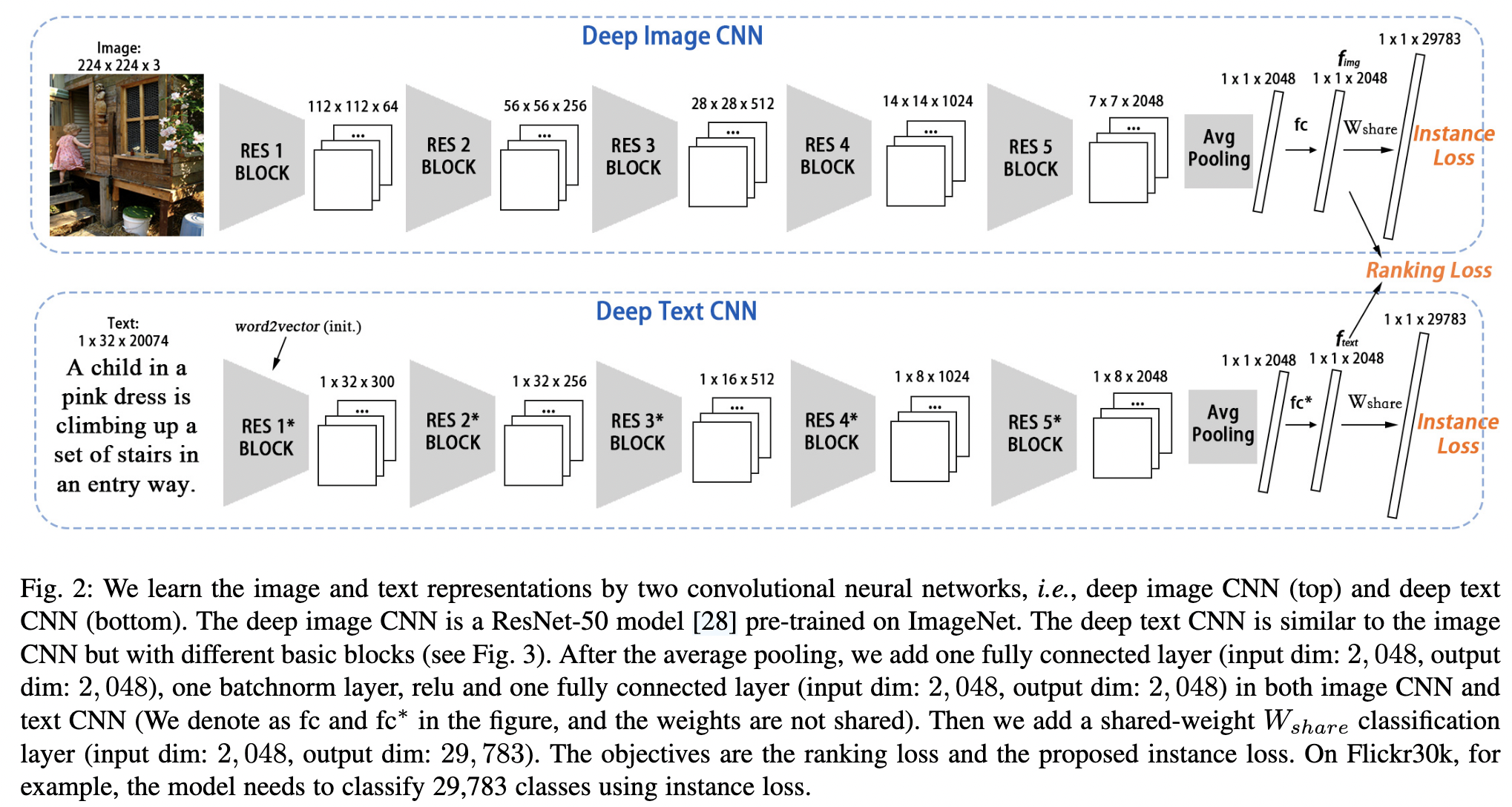
What:
- 用CNN分类113,287类图像(MSCOCO)。1张图像 + 5句描述 当作一个类别,所以才有这么多类。
- 解决 instance-lecel 的 retrieval 问题,更细粒度的检索。用自然语言给出更准确的描述
读前问题:
- 为什么要给每张图都分个类?不会过拟合吗?(答:如果只用一张图像一类,CNN肯定会过拟合,同时,我们利用了5句图像描述(文本),加入了训练
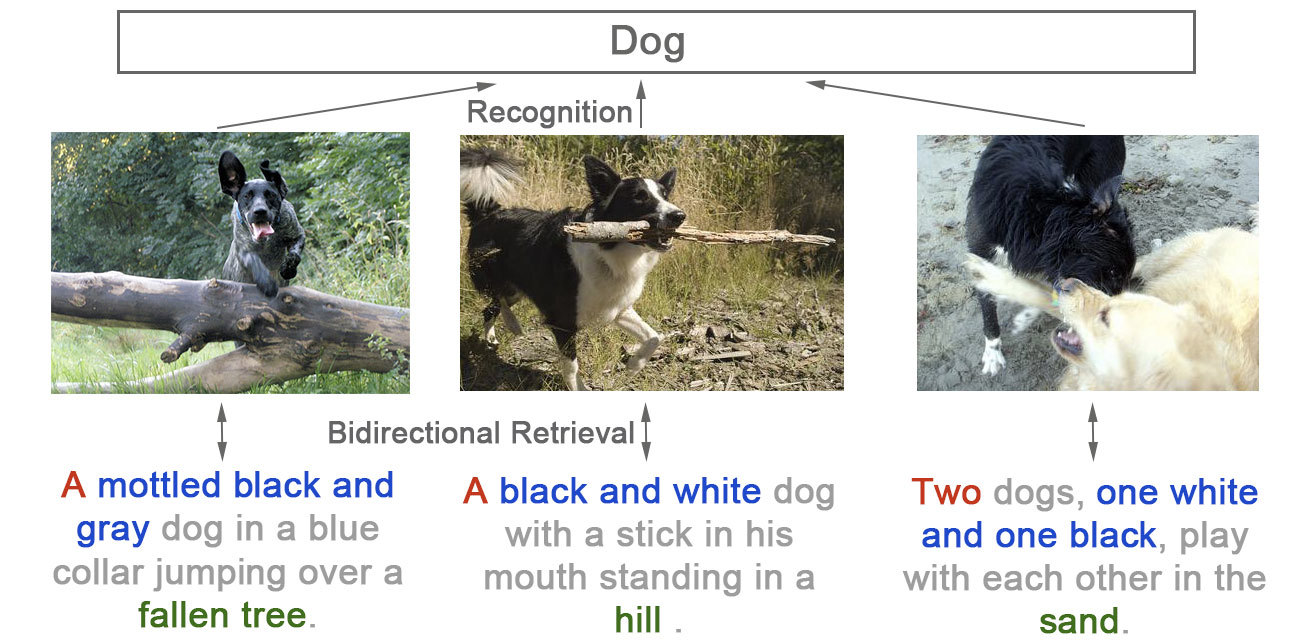
- 如果你在5000张图的image pool中,要找“一个穿蓝色衣服的金发女郎在打车。” 实际上你只有一个正确答案。不像class-level 或category-level的 要找“女性“可能有很多个正确答案。所以这个问题更细粒度,也更需要detail的视觉和文本特征。
- 同时我们又观察到好多之前的工作都直接使用 class-level的 ImageNet pretrained 网络。但这些网络实际上损失了信息(数量/颜色/位置)。以下三张图在imagenet中可能都会使用Dog的标签,而事实上我们可以用自然语言给出更精准的描述。也就是我们这篇论文所要解决的问题(instance-level的图文互搜)。
How:
自然语言:
TextCNN,并行训练+finetune。用了类似ResNet的block。注意到句子是一维的,在实际使用中,用的是 1X2的conv。
Instance loss:
最终的目的是让每一个图像都有区分(discriminative)的特征,自然语言描述也是。所以,为什么不尝试把每一张图像看成一类呢。(注意这个假设是无监督的,不需要任何标注。)极端少样本分类,学到细粒度差别。
结合文本和图像一起训练:
文本和图像很容易各学各的,来做分类。所以我们需要一个限制,让他们映射到同一个高层语义空间。
我们采用了一个简单的方法:在最后分类fc前,让文本和图像使用一个W,那么在update过程中会用一个软的约束,这就完成了(详见论文 4.2)。 在实验中我们发现光用这个W软约束,结果就很好了。(见论文中StageI的结果)
训练收敛:
直接softmax loss,没有trick。
图像分类收敛的快一些。文本慢一些。在Flickr30k上,ImageCNN收敛的快,
TextCNN是重新开始学的,同时是5个训练样本,所以相对慢一些。
instance loss的假设是无监督的,因为我们没有用到额外的信息 (类别标注等等)。而是用了 “每张图就是一类” 这种信息。
更深的TextCNN一定更好么?
相关论文是 Do Convolutional Networks need to be Deep for Text Classification ?
确实,在我们额外的实验中也发现了这一点。在两个较大的数据集上,将文本那一路的Res50提升到Res152并没有显著提升。
一些trick(在其他任务可能不work)
因为看过bidirectional LSTM一个自然的想法就是 bidirectional CNN,我自己尝试了,发现不work。插曲:当时在ICML上遇到fb CNN翻译的poster,问了,他们说,当然可以用啊,只是他们也没有试之类的。
本文中使用的Position Shift 就是把CNN输入的文本,随机前面空几个位置。类似图像jitter的操作吧。还是有明显提升的。详见论文。
比较靠谱的数据增强 可能是用同义词替换句子中一些词。虽然当时下载了libre office的词库,但是最后还是没有用。最后采用的是word2vec来初始化CNN的第一个conv层。某种程度上也含有了近义词的效果。(相近词,word vector也相近)
可能数据集中每一类的样本比较均衡(基本都是1+5个),也是一个我们效果好的原因。不容易过拟合一些“人多”的类。
实验: