
论文阅读:Towards VQA Models That Can Read
Published:
迈向具有阅读能力的 VQA 模型
CVPR 2019
推荐阅读:
视觉问答 Look, Read, Reason & Answer
Abstract
- 研究问题: 视障用户对图像的提问主要涉及阅读图像中的文本。
- 贡献1: 引入“TextVQA数据集”,包含针对 28,408 张图像的 45,336 个问题,需要对文本进行推理才能回答。
- 贡献2: Look, Read, Reason & Answer (LoRRA),读取图像中的文本,在图像和问题的上下文中对其进行推理,并预测答案,该答案可能是基于文本和图像的推论,也可能是由OCR在图像中找到的字符串组成。
- 贡献3: LoRRA 在我们的TextVQA 以及VQA 2.0 数据集上优于现有最先进的VQA 模型。
- 我们发现 TextVQA 上的人类表现和机器表现之间的差距明显大于 VQA 2.0,这表明 TextVQA 非常适合沿着与 VQA 2.0 互补的方向进行基准测试。
1.Introduction
本文的重点是赋予视觉问答(VQA)模型一种新的能力——阅读图像中的文本并通过推理文本和其他视觉内容来回答问题
the ability to read text in images and answer questions by reasoning over the text and other visual content. But today’s VQA models fail catastrophically on questions requiring reading! today’s state-of-art VQA models are predominantly monolithic deep neural networks (without any specialized components). ‘What does it say near the star on the tail of the plane?’
为了回答这些问题,模型必须学会:
- 意识到问题是关于文本的(“……说什么?”)
- 检测包含文本的图像区域(‘15:20’、‘500’)
- 将这些区域的像素表示(卷积特征)转换为符号(“15:20”)或文本表示(语义词嵌入)
- 联合推理检测到的文本和视觉内容以关注正确的区域,例如解决空间或其他视觉参考关系(“飞机尾部……背面”)
- 最后,决定检测到的文本是否需要“复制粘贴”作为答案
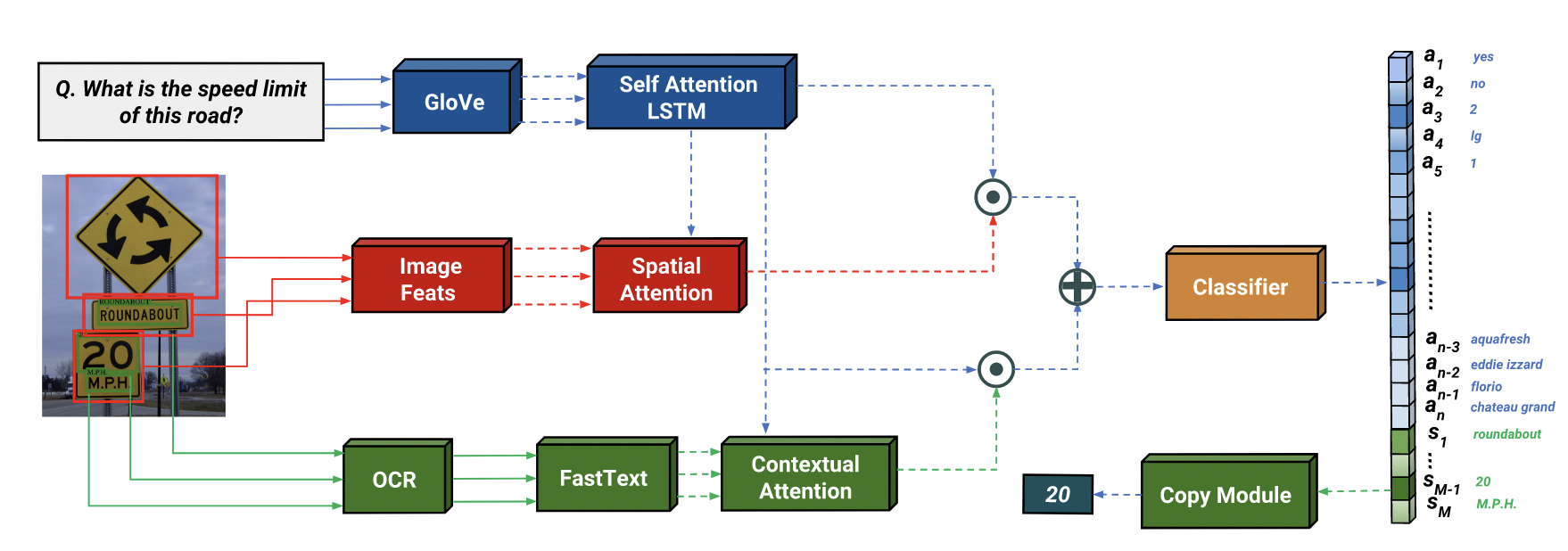
具体来说,我们提出了一种新的 VQA 模型,其中包含 OCR 模块。我们称之为“查看、阅读、推理和回答”(LoRRA)。我们的模型架构将图像中包含文本的区域(边界框)合并为要关注的实体。它还将这些区域中识别的实际文本(例如“15:20”)合并为模型学习推理的信息(除了视觉特征之外)。最后,我们的模型决定生成的答案是否从 OCR 输出中“复制”,或从文本中推断出来(就像现有 VQA 模型中流行的标准判别预测范式一样)。
我们的模型端到端地学习这种机制。虽然目前仅限于 OCR 范围,但我们的模型是赋予 VQA 模型对非结构化外部知识源进行推理的能力的第一步(在本例中是在测试图像中找到的文本)并容纳多个信息流流(在本例中是根据预定词汇预测答案或通过副本生成答案)。
2.Related work
- Visual Representations for VQA Models. VQA 模型通常使用注意力变体来得到和回答问题相关的图像表示。候选框和相关特征是检测网络生成的,然后在空间上关注并以问题表示为条件。在这项工作中,我们扩展了 VQA 模型推理的表示。具体来说,除了候选框之外,我们的模型还关注检测到文本的区域。
The object region proposals and the associated features are generated by using a detection network which are then spatially attended to and conditioned on a question representation.
- Copy Mechanism. 答案直接就是 OCR tokens 还是说 OCR 只是指代了答案。前者通过复制机制实现,基于 pointer generator networks 通过指向上下文中的单词然后将其复制为答案来生成词汇表之外的单词。
3.LoRRA: Look, Read, Reason & Answer
我们假设我们得到一个图像 v 和一个问题 q 作为输入,其中问题由 L 个单词 w1, w2, … wL 组成。
模型包含三个部分:
(i) VQA 组件,用于根据图像 v 和问题 q 进行推理和推断答案;
(ii) 一个阅读组件,允许我们的模型阅读图像中的文本;
(iii) 一个回答模块,它可以从答案空间进行预测,也可以指向阅读组件所阅读的文本.
OCR模块和骨干VQA模型可以是任何OCR模型和任何最近基于注意力的VQA模型。我们的方法与这些组件的内部细节无关。
3.1. VQA Component
首先用预训练的嵌入方法将问题 q 的 words w1, w2, … wL 嵌入,然后用循环网络迭代地对生成的词嵌入编码,的到问题嵌入 fQ(q)。对于图像,视觉特征以卷积从候选框中提取特征的形式被表示为空间特征。我们将这些特征称为 fI (v),其中 fI 是提取图像表示的网络。我们在空间特征上使用注意力机制 fA ,它根据 fI (v) 和 fQ(q) 预测注意力,并给出空间特征的加权平均值作为输出。
然后我们将输出与问题嵌入结合起来。在较高层次上,我们的 VQA 特征\(f_{VQA}(v, q)\) 的计算可以写为:
\[f_{VQA}(v, q) = f_{comb}(f_A(f_I (v), f_Q(q)), f_Q(q))\]3.2. Reading Component
为了添加从图像中读取文本的功能,我们依赖于 OCR 模型,该模型未与我们的系统联合训练。我们假设 OCR 模型可以从图像中读取并返回 word tokens. OCR 模型从图像中提取 M 个单词 s = s1, s2, …, sM,然后使用预先训练的单词嵌入 fO 进行嵌入。最后,我们使用与 VQA 组件相同的架构来获得组合的 OCR 问题特征 fOCR。
\[f_{OCR}(s, q) = f_{comb}(f_A(f_O(s), f_Q(q)), f_Q(q))\]注意,函数 fA 和 fcomb 的参数不与上面的 VQA 模型组件共享,但它们具有相同的架构,只是输入维度不同。
在加权注意力过程中,因为特征乘以权重然后求平均值,所以排序信息会丢失。为了向答案模块提供原始 OCR 标记的排序信息,我们将注意力权重与最终的权重平均特征连接起来。这使得答案模块能够按顺序知道每个标记的原始注意力权重。
3.3. Answer Module
在固定答案空间的情况下,当前的 VQA 模型只能预测固定 token,这限制了词表之外 (OOV) 单词的泛化。由于图像中的文本经常包含训练时未看到的单词,因此很难仅根据预定义的答案空间来回答基于文本的问题。为了推广到任意文本,我们受到指针网络启发,它允许在上下文中指向 OOV 单词。我们通过添加对应于 M OCR tokens的动态组成来扩展我们的答案空间。该模型现在必须预测答案空间中 N +M 个项目的概率 (p1, …, pN , …, pN+M ),而不是原始的 N 个项目。
我们选择具有最高概率 pi 的索引作为我们预测答案的索引。如果模型预测的索引大于 N(即答案空间中最后 M 个标记),我们直接“复制”相应的 OCR tokens作为预测答案。因此,我们的回答模块可以被认为是“如果需要就复制”模块,它允许使用 OCR 令牌从 OOV 单词中回答。
对于所有组件,用于预测答案概率的最终方程 fLoRRA 可写为:
\[f_{LoRRA}(v, s, q) = f_{MLP} ([f_{VQA}(v, q); f_{OCR}(s, q)])\][;]指 concat, fMLP 是一个两层前馈网络,它将二进制概率预测为每个答案的 logits。我们选择使用 logits 进行二元交叉熵,而不是通过 softmax 计算概率,因为它允许我们处理答案可以同时存在于实际答案空间和 OCR 标记中的情况,而不会因为预测其中任何一个而受到惩罚(logits 的可能性是独立的)彼此)。请注意,如果模型选择复制,它只能生成其中一个 OCR token 作为预测答案。 8.9% 的 TextVQA 问题只能通过组合多个 OCR tokens 来回答;我们将其留作未来的工作。
3.4. Implementation Details
我们的 VQA 组件基于 VQA 2018 挑战赛获胜者条目 Pythia v0.1。我们修改后的实现 Pythia v0.3,在超参数(例如问题词汇量的大小、隐藏维度)方面略有变化,实现了单模型最先进的 VQA 准确度。
Pythia 受到自下而上自上而下注意网络(2017 年 VQA 获胜者)基于检测器的边界框预测方法的启发,该方法又具有与 VQA 2016 年获胜者类似的多模态注意机制,它依赖于基于网格的特征。
在 Pythia 中,对于空间特征 fI (v),我们依赖于图像的基于网格和区域的特征。基于网格的特征是通过平均池化预训练 ResNet-152 的 res-5c 块中的 2048D 特征获得的。基于区域的特征是从改进的 Faster-RCNN 模型的 fc6 层中提取的,该模型在 Visual Genome 对象和属性上进行训练,在训练过程中,我们按照(Pythia v0. 1: the winning entry to the vqa challenge 2018. arXiv preprint arXiv:1807.09956, 2018.)中的方式微调 fc7 权重。
我们使用预先训练的 GloVe 嵌入和自定义词汇表(VQA 2.0 中的前 77k 问题词)来进行问题嵌入。 fQ 模块将 GloVe 嵌入传递给具有自注意力的 LSTM ,以生成问题的句子嵌入。对于 OCR,我们运行 Rosetta OCR 系统来为我们提供字符串 s1, …, sN 。 OCR 令牌首先使用预训练的 FastText 嵌入 (fO) 进行嵌入,它甚至可以为 OOV 词元生成单词嵌入。
在 fA 中,嵌入 fQ(q) 的问题用于获得自上而下,即对 fO(s) OCR 标记特征和 fI (v) 图像特征的特定任务关注。然后根据注意力权重对特征进行平均,以获得 OCR 标记和图像特征的最终特征表示。在图像特征的情况下,最终的网格级和基于区域的特征被连接起来。对于 OCR 令牌,注意力权重连接到最终关注的特征,如第 2 节中所述。 3.1.最后,在 fcomb(x, y) 中,使用特征的元素级/哈达玛积 ⊗ 融合所考虑的两个特征嵌入。来自 fOCR(s, q) 和 fV QA(v, q) 的融合特征被连接并通过 MLP 来生成 logits,从中选择与最大 logit 索引相对应的单词作为答案。
4.TextVQA
5. Experiments
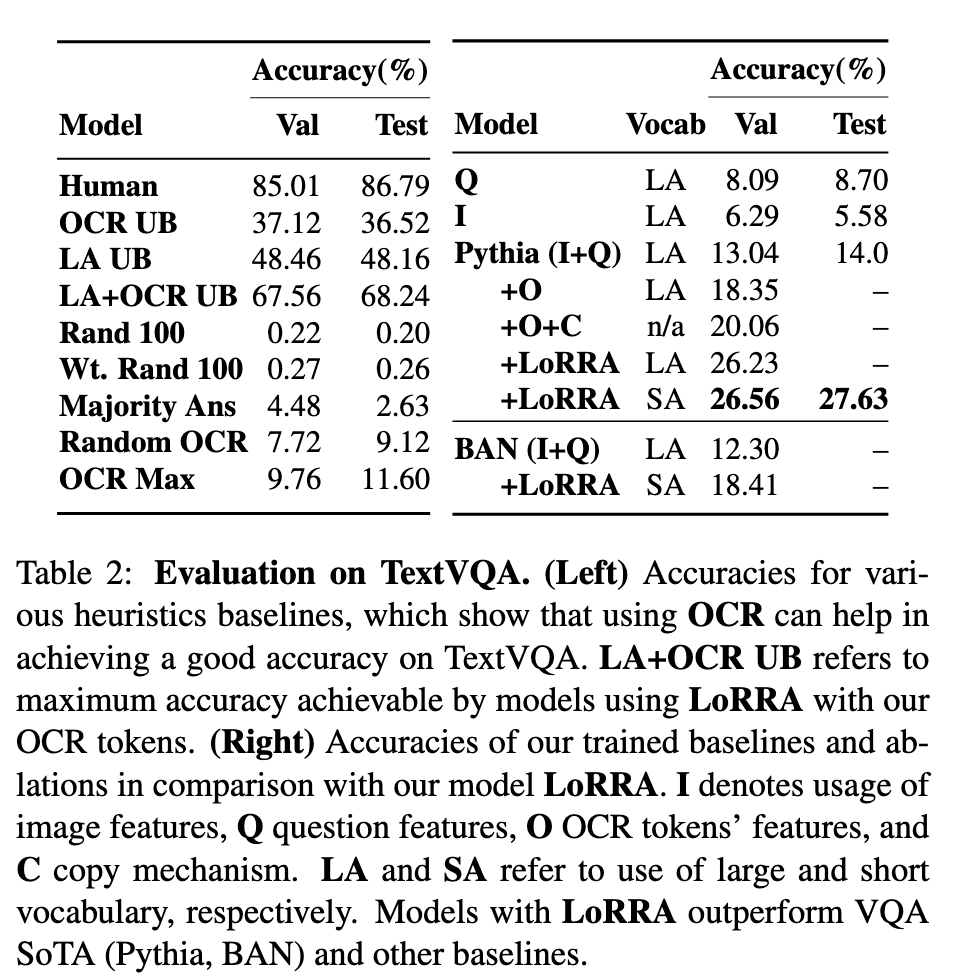
我们将 TextVQA 分为训练、验证和测试部分,大小分别为 34,602、5,000 和 5,734。从 Open Images v3 训练集中收集的 TextVQA 问题被随机分为训练集和验证集。各组之间没有图像重叠。对于我们的方法,我们使用大小为 3996 的词汇 SA,其中包含在训练集中至少出现两次的答案。对于不使用复制机制的基线来说,这个词汇量太有限了。为了给他们一个公平的机会,我们还创建了一个更大的词汇表 (LA),其中包含 8000 个最常见的答案。
Baselines.
(i) 仅问题(Q):我们仅使用 LoRRA 的 fQ(q) 模块来预测答案,其余特征被清零。
(ii) 仅图像 (I):与 Q 类似,我们仅使用图像特征 fI (v) 来预测答案。 Q 和 I 无法访问 OCR 词元并从 LA 进行预测。
Upper Bounds and Heuristics.
这些主要评估使用我们的 OCR 模块检测到的 OCR tokens 可以实现的上限以及数据集中的基准偏差。
(i) OCR UB:如果可以直接从 OCR tokens 构建答案(并且始终可以正确预测),则可以获得的精度上限。
(ii) LA UB:如果 LA 中存在正确答案,则始终预测正确答案的精度上限。
(iii) LA+OCR UB:(i) + (ii) - 通过预测正确答案(如果存在于 LA 或 OCR tokens 中)可以获得的上限准确度。
Ablations.
我们通过结合或交替使用阅读组件和回答模块来创建 LoRRA 方法的几种消融。
(i) I+Q:这种消融是 VQA 2.0 的最先进技术,并且不使用任何类型的 OCR 功能;
(ii) Pythia+O:Pythia 以 OCR 功能作为输入,但没有复制模块或动态答案空间;
(iii) Pythia+O+C:(ii) 具有复制机制,但没有固定答案空间,即模型只能根据 OCR tokens 进行预测。当我们向模型添加复制模块和动态答案空间时,会使用缩写 C。 我们的完整模型对应于 Pythia 附带的 LoRRA。我们还将具有小答案空间 (SA) 的 Pythia+LoRRA 与具有大答案空间 (LA) 的版本进行比较。
Experimental Setup.
We develop our model in PyTorch [35]. We use AdaMax optimizer [26] to perform backpropagation [29]. We predict logits and train using binary cross-entropy loss. We train all of our models for 24000 iterations with a batch size of 128 on 8 GPUs. We set the maximum question length to 14 and maximum number of OCR tokens to 50. We pad rest of the sequence if it is less than the maximum length. We use a learning rate of 5e-2 for all layers except the f c7 layers used for fine-tuning which are trained with 5e-3. We uniformly decrease the learning rate to 5e-4 after 14k iterations. We calculate val accuracy using VQA accuracy metric [10] at every 1000th iteration and use the model with the best validation accuracy to calculate the test accuracy. All validation accuracies are averaged over 5 runs with different seeds.
Results.
LoRRA 和 LA+OCR UB 之间 41% 的差异代表了当前 OCR 代币和 LA 建模的改进空间。
仅问题 (Q) 和仅图像 (I) 基线分别获得 8.09% 和 6.29% 的验证准确度,这表明数据集不存在显着偏差。图像和问题。
通过将 OCR tokens (Pythia+O) 输入到模型中,准确率跃升至 18.35%;这支持了 OCR tokens 确实有助于预测正确答案的假设。
Pythia+O+C 仅通过 OCR tokens 预测答案即可实现 20.06 的验证准确度,进一步增强了 OCR 的重要性
我们的 LoRRA (LA) 与 Pythia 模型的性能优于所有消融模型。最后,通过将固定答案空间 LA 更改为 SA 进行轻微修改,使模型能够更频繁地根据 OCR tokens 进行预测,进一步提高了性能。
虽然 LoRRA 在 TextVQA 验证集上的准确率可以达到 26.56%,但与人类的 85.01% 和 LA+OCR UB 的 67.56% 的表现存在很大差距。